 QQ咨询
QQ咨询
spark hadoop 比較
其實我本來想寫篇介紹spark的,但網路上參考文章實在太多了,我自己也只跑過簡單的範例程式,就不誤人子弟了
至於為何標題這樣取呢? 因為小弟在學習spark與複習hadoop的過程產生了很多疑問
為何要用這個不用那個?
這個為何比那個好?
所以我就把我survey的階段性結果整理成好幾個比較,這篇在未來的未來還會再新增,伴隨我與spark越來越熟的過程吧!
在開始比較前先分享兩篇文章,對於入門認識spark會有很大的幫助
一篇是我實驗室的學長vetom寫的spark架構介紹文
Big Data 新寵兒 Apache Spark 系列 – Spark 與 Hadoop 初次見面篇
一篇是介紹spark強大的獨家秘方RDD的文章
Spark RDD (Resilient Distributed Datasets) 詳細圖文介紹
Q1: spark比起hadoop好在哪?

這個問題我想是剛接觸spark的人共通的疑惑,大家會認識這個term都是聽到在某比賽,spark用了比hadoop還要少的node數,卻快了40倍以上的速度吧!
至於為何spark會快那麼多呢? 關鍵字就是in-memory,所有階段性的output都儲存於內存,因此減少了大量的I/O latency,但可以就這樣說spark比hadoop好嗎? 這是不正確的,因為hadoop這個字是一個龐大的家族,包含了hdfs、map reduce、hive等.. 所以我們應該重新定義這個問題,spark比起map reduce好在哪?
Q1.1: spark比起map reduce好在哪?
在vetom的介紹文有提到,map reduce會有嚴重的效能瓶頸,在於他每一個階段性輸出都必須存到檔案儲存系統,如果我們要跑有迭代的演算法,例如kmeans每次的k都是根據上次的 output資料點,那每做一次就要去讀寫一次hdfs,自然造成效能低落,不過這也怪不了map reduce,畢竟他一開始就不是為了解決這種問題XD 只能說是大家的需求超過他的能力了
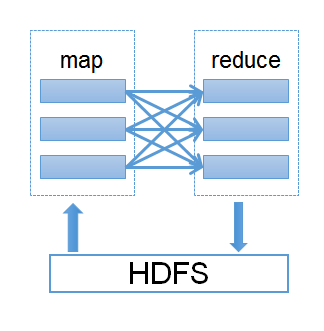
因此,spark的核心技術RDD有效的解決了這個問題(不懂RDD就參考第2篇介紹文),每次階段性輸出到RDD上,RDD還是存於內存,不管幾次的map reduce,transformation依然有很高的執行效率
因此有人提到,spark是很有可能取代掉map reduce,成為新的分散式運算的主流演算法
Q2: 檔案儲存使用HDFS還是S3?
這個問題產生於看了AWS EMR的官方教學,幾乎都是把檔案放在S3上面,但網上把檔案丟在HDFS的人也不在少數,可以說是各有支持者,因此我就看了幾篇文章 (主要是這篇Storing Apache Hadoop Data on the Cloud – HDFS vs. S3) 比較了一下兩者的優劣
HDFS的優缺點:
HDFS的讀寫資料效能是大家公認快於S3的,畢竟是與spark在同一個cluster,不過在這點上,spark僅需在起始讀取資料及action後寫入資料,其餘階段性結果都是透過RDD存於記憶體,因此差距好像也沒那麼大(我自己覺得啦,有錯誤請指正)
而最大的缺點就是擴充性,如果要能夠儲存更多的資料,必需新增更多節點才能有較大的硬碟驅動,並且hdfs的資料在cluster terminate後就會消失
S3的優缺點:
反之HDFS,S3可以無限的儲存資料在上面,只要你要付更多的摳摳XD,具有良好的擴充性,並且在群集關閉後資料也存在
缺點就是效能比HDFS來的差,且有5GB的每次讀取大小限制
在使用EMR方面,S3比起HDFS看來方便許多,5GB的限制也能分割資料來解決,使用AWS家族的東西彈性就是比較高,不過兩者並沒有說誰優誰 劣,如果我是自己架可能就會選擇HDFS或cassandra吧XD,AWS也有一套nosql是DynamoDB,等有空再研究囉!
Q3: sparkSQL vs. hive
施工中
Q4: 機器學習要用MLlib還是Mahout?
施工中
同事的問題
Q5: spark真的只有改成in-memory就好那麼多嗎? 應該還有其他的吧
spark的API都是用scala寫的,在很多程度上對於效能有優化(例如map沒有全部都計算),所以就算不存於記憶體也可以比map reduce快個10倍,當然如果加上in-memory就是百倍了..
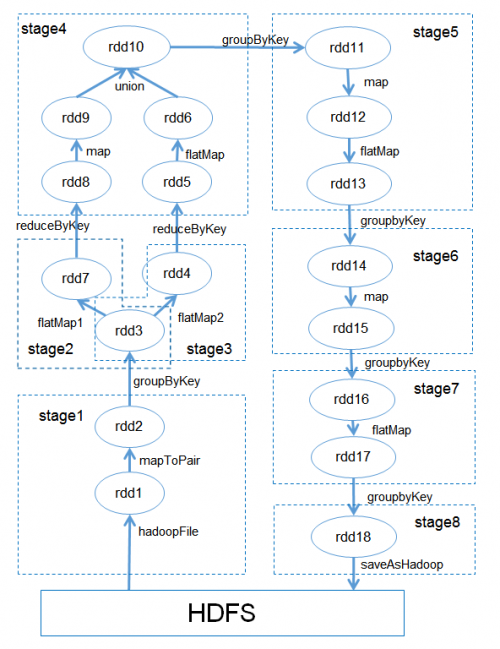
Q6: RDD為何每次transformation都要建一個新的RDD?
下面是原始RDD論文提到的
RDDs provide a highly restricted form of shared mem-ory: they are read-only, partitioned collections of records that can only be created through deterministic transfor-mations (e.g.,map, join and group-by) on other RDDs.These restrictions, however, allow for low-overhead fault tolerance. In contrast to distributed shared memory sys-tems [24], which require costly checkpointing and roll-back, RDDs reconstruct lost partitions through lineage:an RDD has enough information about how it was de-rived from other RDDs to rebuild just the missing parti-tion, without having to checkpoint any data. AlthoughRDDs are not a general shared memory abstraction, they represent a sweet-spot between expressivity, scalabilityand reliability, and we have found them well-suited for awide range of data-parallel applications
主要說RDD會做成read-only 是為了容錯方便 不需要建立太多check-point
每個RDD都可以透過lineage架構追朔到父RDD 當有發生意外可以re-compute
所以他這樣就不需要像HDFS那樣的備份機制
Q7: 為何map reduce不做in-memory
其實只要導入RDD就可以了,但這不是同一個開發團隊做的
in-memory主要是為了解決迭代的需求,主要是for資料分析機器學習比較多這種algorithm
上一篇介紹了如何設定AWS EMR,現在我們想要在設定好的spark上跑經典的wordCount程式,
俗話說工欲善其事,必先利其器,既然要打程式碼怎麼可以沒有IDE(當然除非你是記事本男子漢….請見男子漢理論)
真正的男子漢 programmer 是不會用那些亂七八糟,花枝招展的,所謂整合開發環境。
真正的男子漢 programmer 就是直接用 emacs, 或是 vi 這些男子漢編輯器直接寫程式。
如果你不知道這是甚麼東東,簡單來說,就是男子漢用的”記事本”。
當然在花枝招展,看來很娘的 Wxxxxws下要找到這些男子漢編輯器有一定難度,
但這絕對難不倒一個真正的男子漢 programmer。
另外真正的男子漢也不會用那些亂七八糟,花枝招展的所謂應用程式寫網頁。
真正的男子漢就是直接用 emacs, 或是 vi 這些男子漢編輯器直接寫 HTML,
因為那些亂七八糟,花枝招展的所謂應用程式寫出來的網頁
加了一大堆亂七八糟的 tag 根本沒有人看得懂。
真正的男子漢也不會用那些亂七八糟,花枝招展的所謂應用程式寫論文。
真正的男子漢就是直接用 emacs, 或是 vi 這些男子漢編輯器直接寫 latex。
因為那些亂七八糟,花枝招展的所謂應用程式寫出來的論文,字型醜的要命,
圖還會亂跑,換一台電腦就換一個樣子,一點也不像男子漢做出來的東西。
最後你可以看出真正的男子漢 programmer 不管做什麼事,
都只用男子漢編輯器就能搞定,這就是成為男子漢 programmer 的重點。
當然最好還是用 ed 這種神物,只是現存看過 ed 的 programmer
可能比看過”真理”的煉金術士還少,在此就不苛求了。
屁話看完XD
我打算先在intellij IDEA上run一個local的範例程式,跑過後包成jar檔submit到EMR上執行,input跟ouput都放在S3上面
首先在intellij安裝scala跟SBT plugin (到settings -> plugins輸入關鍵字安裝),裝好後開啟一個SBT專案,名字隨便輸入,其他都不用改,indexing完後會看到以下目錄結構
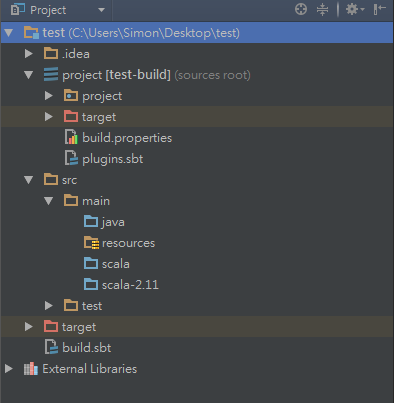
在src > main > scala裡new一個scala class,就叫wordCount吧,貼上下面這段程式碼
import org.apache.spark._
/** Computes an approximation to pi */
object wordCount extends Logging {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi")
val spark = new SparkContext(conf)
val hadoopConf = spark.hadoopConfiguration
hadoopConf.set("fs.s3n.impl", "org.apache.hadoop.fs.s3native.NativeS3FileSystem")
hadoopConf.set("fs.s3n.awsAccessKeyId", "**********")
hadoopConf.set("fs.s3n.awsSecretAccessKey", "*****************")
val textFile = spark.textFile("s3n://emr-datacollect/input/spam.data.txt")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("s3n://emr-datacollect/output")
}
}
access key跟私鑰自己到AWS後台增一個,我就不多說了,
貼上程式碼後,你會看到滿江紅,原因是spark libaray還沒設定,到根目錄的build.sbt加上下面這行
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.5.0"
然後refresh就發現紅字都不見啦~
再跑程式前提醒你,先到s3你指定的目錄放上你要計算word count的資料,然後設定output路徑,千萬不要建立output這個folder,spark輸出會幫你建起來
設定configuration -> Application,輸入如下圖
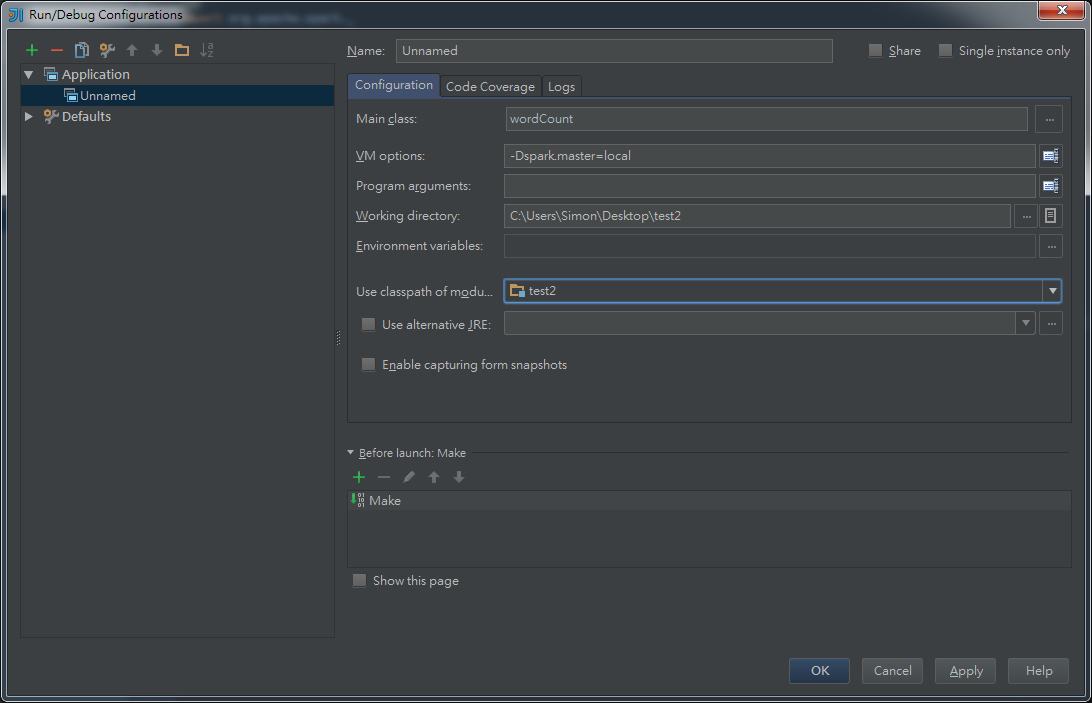
然後就可以run啦,如果出現java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.不用理他,好像是windows跑分散式還要再裝什麼,反正不影響結果
打開你的S3就可以看output結果了
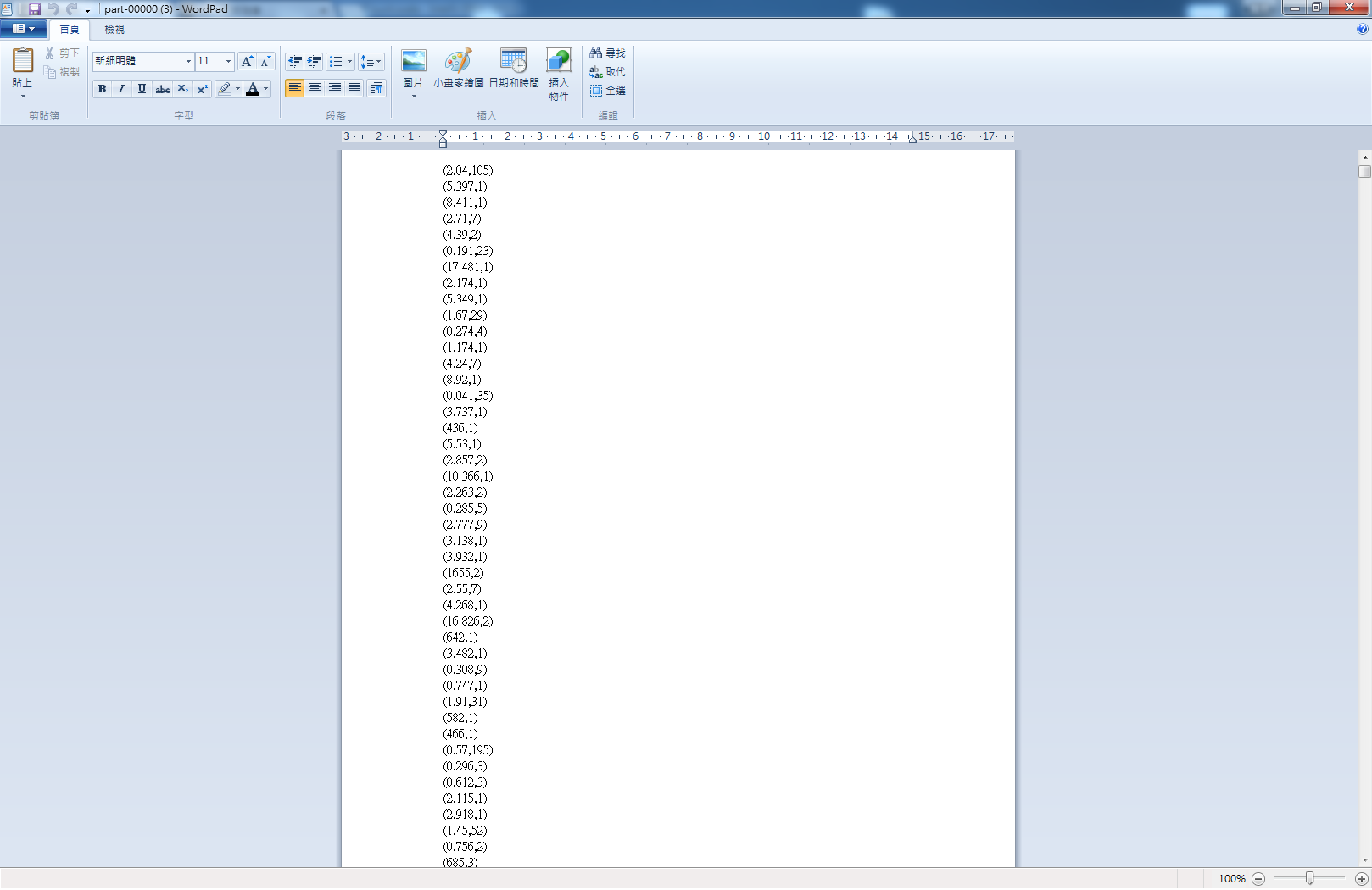
本地端跑完沒問題後,就包成jar檔丟到EMR上
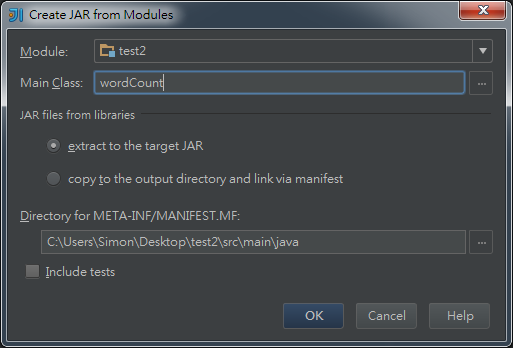
ProjectStructure -> Artifacts -> +JAR -> From modules…. ->
main class就選擇wordCount
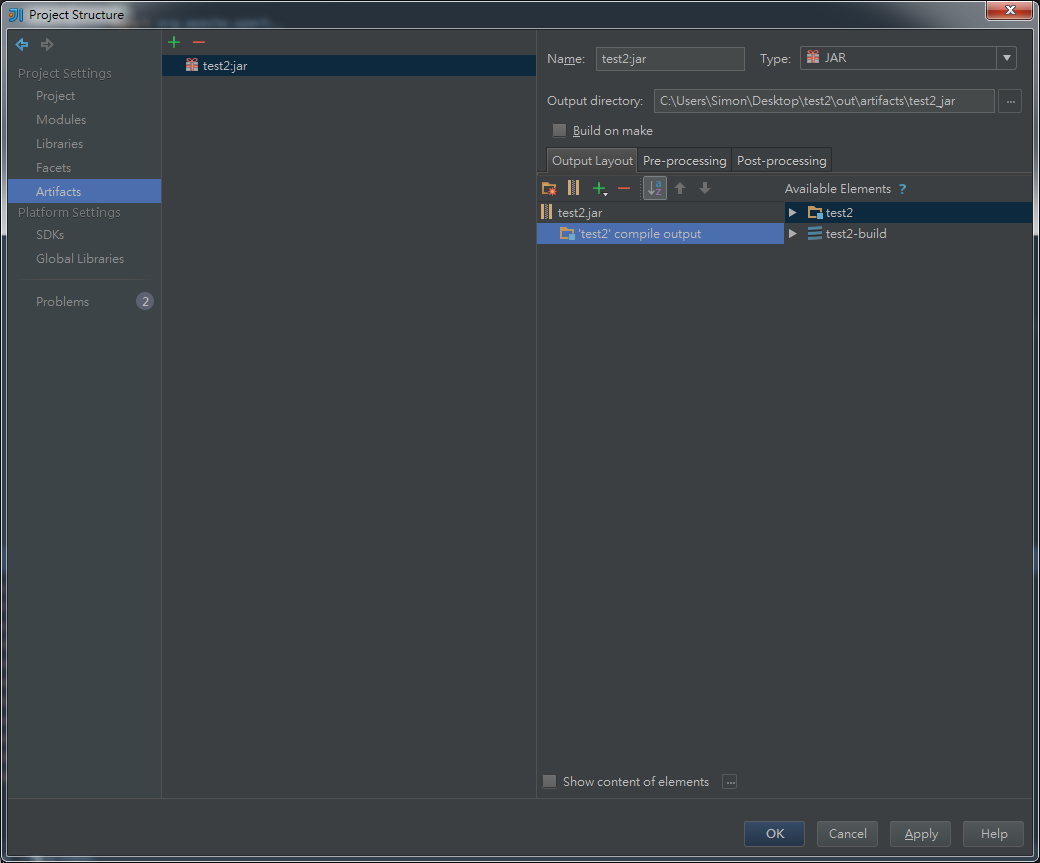
再來要把所有依賴包全部勾掉,不然上去會跟EMR的spark衝到 (exit code 10 ..fk..)如下圖只剩class本身
然後Build -> BuildArtifacts -> Rebuild
就可以看到多了一個out的資料夾,裡面有剛剛輸出的jar檔,在把jar檔丟到s3上面
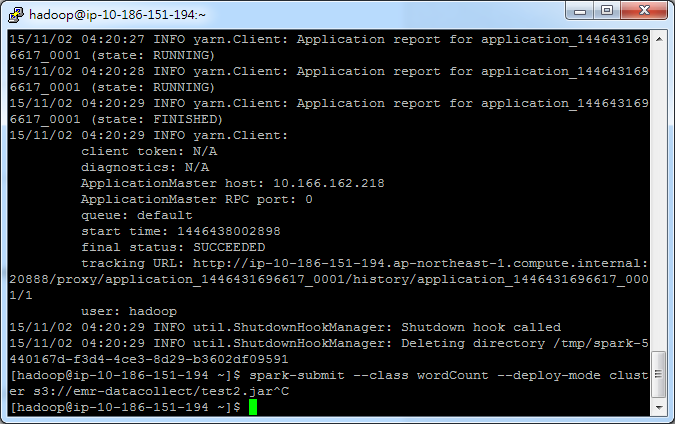
SSH進EMR,輸入以下這段指令
spark-submit --class wordCount --deploy-mode cluster s3://emr-datacollect/test2.jar
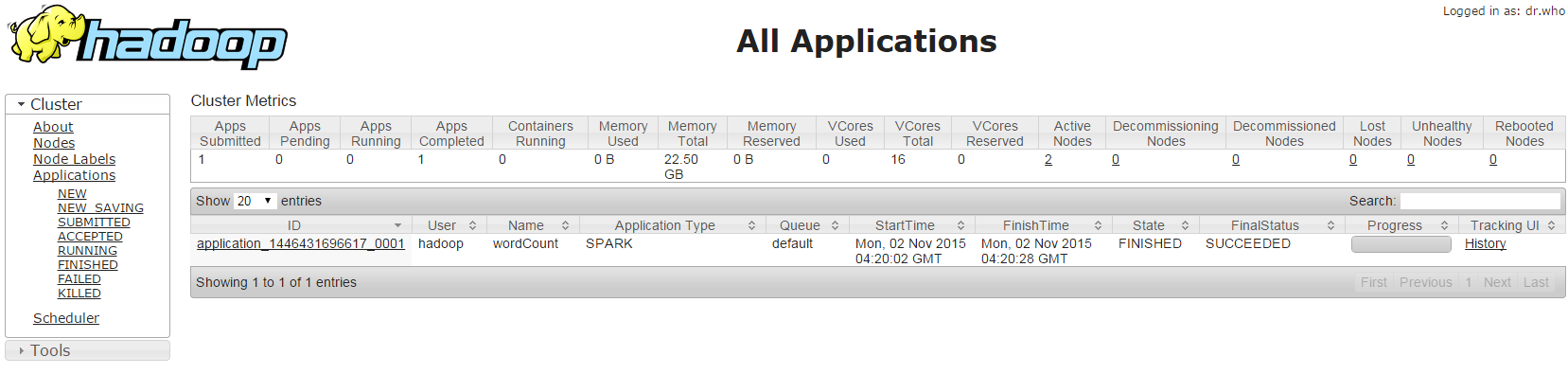
跑完了去S3看結果

檔案被切割成兩份,我想是分下去做我沒設定reduce吧XD (不熟隨便講的XDD)連到後台可以看到剛剛跑成功的wordCount
後記:
AWS kinesis 與 spark streaming 使用
今次的 topic 是我開始玩弄 spark 以來遇到最多瓶頸的一次,過程真的非常受挫,不過歷經了約7天的掙扎算是勉強兜起來了,
就來談談整個設定過程,及過程中遇到的阻礙
已經可以 run 一個基本的 spark 分散式運算了,下一步就是把前端接收資料的串流 kinesis 建起來(可以參考EMR設定那篇最上面的圖),這時我理所當然的開始翻起 kinesis 的 document,嘗試去 run 它的範例,然後就遇到了第一個瓶頸..
阻礙1: 官方文件及範例提供的功能與我的需求不合
kinesis 分成了接收端(也就是接收資料)跟應用端(應用接收進來的資料),大致看了一下原理就把他這篇提供的程式碼載下來 run 股票交易,看了一下這 java 的 code 跑了之後發現,它接收的資料是 random 產生一筆一筆的 json 數據丟進 kinesis,而沒有提供任何接收 server 檔案的接口,我有看過整份文件,真的沒有…
但我目的是想把 server 的 log 檔即時讀進 kinesis 做串流,因此就不停地 google 看 kinesis 到底有沒有接口,然後找到了這篇
How to put data from server to Kinesis Stream
有人提到了用我之前架構EFK的 fluentd,看來 kinesis 是真的沒有,真的是OOXX,那介紹就不該放這張害我以為有接口..如果我有誤會請指正
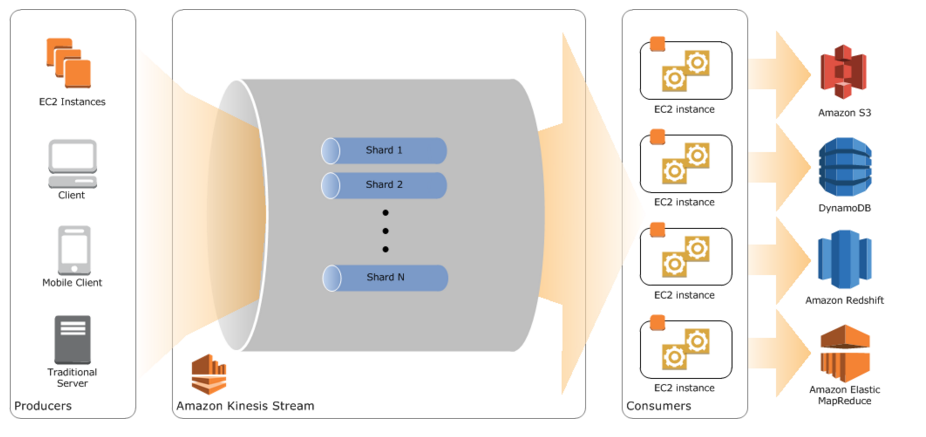
之後就開始嘗試在檔案與 kinesis 間插進 fluentd,方法一樣是在 conf 檔裡加入連到 kinesis 的 tail,但因為同時也要送到 elasticSearch,所以要用 copy
<match *.**>
type copy
<store>
type secure_forward
shared_key FLUENTD_SECRET
self_hostname node1.example.com
secure true
ca_cert_path /path/to/certificate/ca_cert.pem
<server>
host **.**.***.***
</server>
</store>
<store>
type kinesis
stream_name *******
aws_key_id **************
aws_sec_key ******************
region ap-northeast-1
random_partition_key true
</store>
</match>
然後就可以看到 kinesis 上的 put records 有資料接進來了
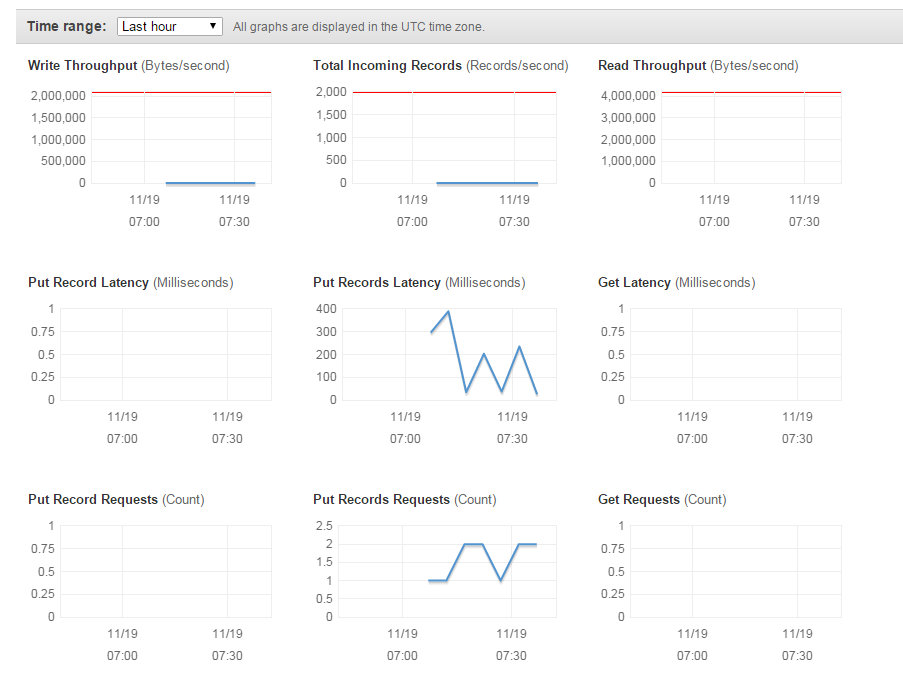
怎麼設定 kinesis 就 skip 了,設定個 shard 數量就可以,他有提供一個公式讓你計算需要幾個 shard (檔案大小之類的),我覺得太麻煩所以就先隨便設成兩個XD接收端串通後,我就在想應用端是要與 spark 連接做即時資料處理,所以 kcl 不該是像範例一樣自己寫,而是要去 spark 找有甚麼接口實作了 kcl,到此為止 kinesis 官方文件已經跟垃圾一樣了= =,我浪費了多少青春年華阿,看來那文件根本是寫給其他input output 端去實作的…
spark 提供了一個資料串流服務叫 spark streaming

它可以即時接收不同平台來的串流資料,然後在 spark 上批次執行運算,所以如果跑下去就會一直在背景執行了,除非你強制 stop,停止方式: $yarn application -kill $ApplicationId
圖上看到他與 kinesis 是有 plugin 連接的,因此我就很開心的覺得快搞定了,殊不知遇到我最大的障礙
阻礙2: spark 設定知識不足
跟 run spark 一樣,要先在 local 端執行起來,第一步要先安裝 library
libraryDependencies += "org.apache.spark" % "spark-streaming-kinesis-asl_2.10" % "1.5.0
或者外部透過 maven 安裝都可以
再來參考的官方範例來改一改
spark streaming kinesis wordcount範例
以下是我的 code
object wordCount{
def main(args: Array[String]) {
val accessKey = "**************
val secretKey = "******************
//val credentials = new DefaultAWSCredentialsProviderChain().getCredentials()
val credentials = new BasicAWSCredentials(accessKey, secretKey)
val kinesisClient = new AmazonKinesisClient(credentials)
val streamName = "********
val endpointUrl = "https://kinesis.ap-northeast-1.amazonaws.com"
kinesisClient.setEndpoint(endpointUrl)
val numShards = kinesisClient.describeStream(streamName).getStreamDescription().getShards().size
// In this example, we're going to create 1 Kinesis Receiver/input DStream for each shard.
// This is not a necessity; if there are less receivers/DStreams than the number of shards,
// then the shards will be automatically distributed among the receivers and each receiver
// will receive data from multiple shards.
val numStreams = numShards
// Spark Streaming batch interval
val batchInterval = Seconds(10)
// Kinesis checkpoint interval is the interval at which the DynamoDB is updated with information
// on sequence number of records that have been received. Same as batchInterval for this
// example.
val kinesisCheckpointInterval = batchInterval
// Get the region name from the endpoint URL to save Kinesis Client Library metadata in
// DynamoDB of the same region as the Kinesis stream
val regionName = RegionUtils.getRegionByEndpoint(endpointUrl).getName()
// Setup the SparkConfig and StreamingContext
val sparkConfig = new SparkConf().setAppName("KinesisWordCountASL")
val ssc = new StreamingContext(sparkConfig, batchInterval)
// Create the Kinesis DStreams
val kinesisStreams = (0 until numStreams).map { i =>
KinesisUtils.createStream(ssc, "KinesisWordCountASL", streamName, endpointUrl, regionName,
InitialPositionInStream.LATEST, kinesisCheckpointInterval, StorageLevel.MEMORY_AND_DISK_2,
accessKey, secretKey)
}
// Union all the streams
val unionStreams = ssc.union(kinesisStreams)
// Convert each line of Array[Byte] to String, and split into words
val words = unionStreams.flatMap(byteArray => new String(byteArray).split(" "))
// Map each word to a (word, 1) tuple so we can reduce by key to count the words
val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _)
val hadoopConf = ssc.sparkContext.hadoopConfiguration
hadoopConf.set("fs.s3n.impl", "org.apache.hadoop.fs.s3native.NativeS3FileSystem")
hadoopConf.set("fs.s3n.awsAccessKeyId", "********")
hadoopConf.set("fs.s3n.awsSecretAccessKey", "******************")
wordCounts.saveAsTextFiles("s3n://emr-datacollect/output/test/")
// Print the first 10 wordCounts
wordCounts.print()
// Start the streaming context and await termination
ssc.start()
ssc.awaitTermination()
}
}
大概就是設定好批次執行的間隔時間(10秒),這邊要注意時間間隔不能小於你處理資料的時間,不然會出現重複資料,至於怎麼看處理資料時間我不知 道…我是看到重複才把時間調長XDD,然後把 kinesisStreams 宣告起來,每隔10秒就把撈到的資料做 wordCount 存到S3上
切記切記,在 local 端執行 spark streaming 一定要設定 core 數量是你 shard 數量的2倍,因為運作上,他會用一半的 core 來接收資料,如果 core 太少就只會收資料不會處理資料了!
在我的例子需要把 core 設成4個,因為2個 shard,在 sparkConf 後加上 .setMaster[“local[4]”] 即可
接著就在本地端 run 成功啦!每段間隔就收到一個 output
之後就跟之前一樣,把程式包成 jar 上傳到 EMR 上,特別注意,因為 spark shell 上沒有支援這些高級接口(也就是 kinesis ),所以要把 spark-streaming-kinesis-asl_2.10 及相關 library 也包進 jar 檔,除了 spark-core 與 spark-streaming,不小心包進來就會發生跟之前一樣的 exit code 10 的problem我本來以為放到 EMR 上 run 會跟在 local 一樣順,殊不知一跑下去s3居然完全接不到資料,我明明已經把 core node 調成4個了,還是超貴的 xlarge (誤),就去看了 spark 後台,發現不管我執行什麼都只有2個 core 會 run,不管是計算 pi 的範例還是什麼都是2個,就算把 core node 調成一個,他還是會分成2個 execution,這才發現 spark default 應該是2個計算執行緒
因此我看了一些文章,嘗試在 spark-submit 後加上一些硬參數像是 –num-executors、–executor-cores,但一點屁用都沒有啊!!!
我是用 EMR 快速建立 spark 的,沒有自己去設定那些參數,所以對於設定那端過於逃避了,心態問題…睡了一晚後,隔天打起精神開始翻spark yarn configuration, 看到了 spark.executor.instances,然後它後面說明推薦用 spark.dynamicAllocation.enabled,會自動根據你的 work 分配 core 數量,於是我就把 spark.dynamicAllocation.enabled 加到了 spark 設定檔裡 (/usr/lib/spark/conf/spark-defaults.conf),後來出現了資料真的是痛哭流涕…抓著 UL 一直碎念雖然他不屌我,但你以為這樣就可以開心慶祝了嗎? 不..又遇到問題了
阻礙3: 粗心大意
開心的一段時間,看了 kinesis 後台整個崩潰了,get request 完全沒有接到東西,查了一下s3上的資料夾每一個週期也都沒有接到資料,又花了半天再找到底是程式哪端出問題了,後來才發現是我 kinesisStream 沒有加上 access key = =+,因為在範例上是用 cli 的 default key,而 local 端我也有設定所以就過了,但在 EMR 上不吃這套,所以我才去查 KinesisUtils.createStream 有沒有吃 key 的參數,把 key 加上去才成功接到資料,這裡我應該要能較快反應問題點出在哪,太過大意與浪費時間了
後記
- shard 數量
- batch time 的選擇
- 為何 –num-executors、–executor-cores 沒有動作