QQ咨询
QQ咨询
AWS EMR配置使用教程
EMR是amazon提供的整合分散資料處理平台,最大的好處就是與AWS家族的各種服務綁在一起(EC2、cloudWatch、S3等等),節省了許多叢集配置的時間,並可彈性配置task node,下圖是提供的整合服務架構:
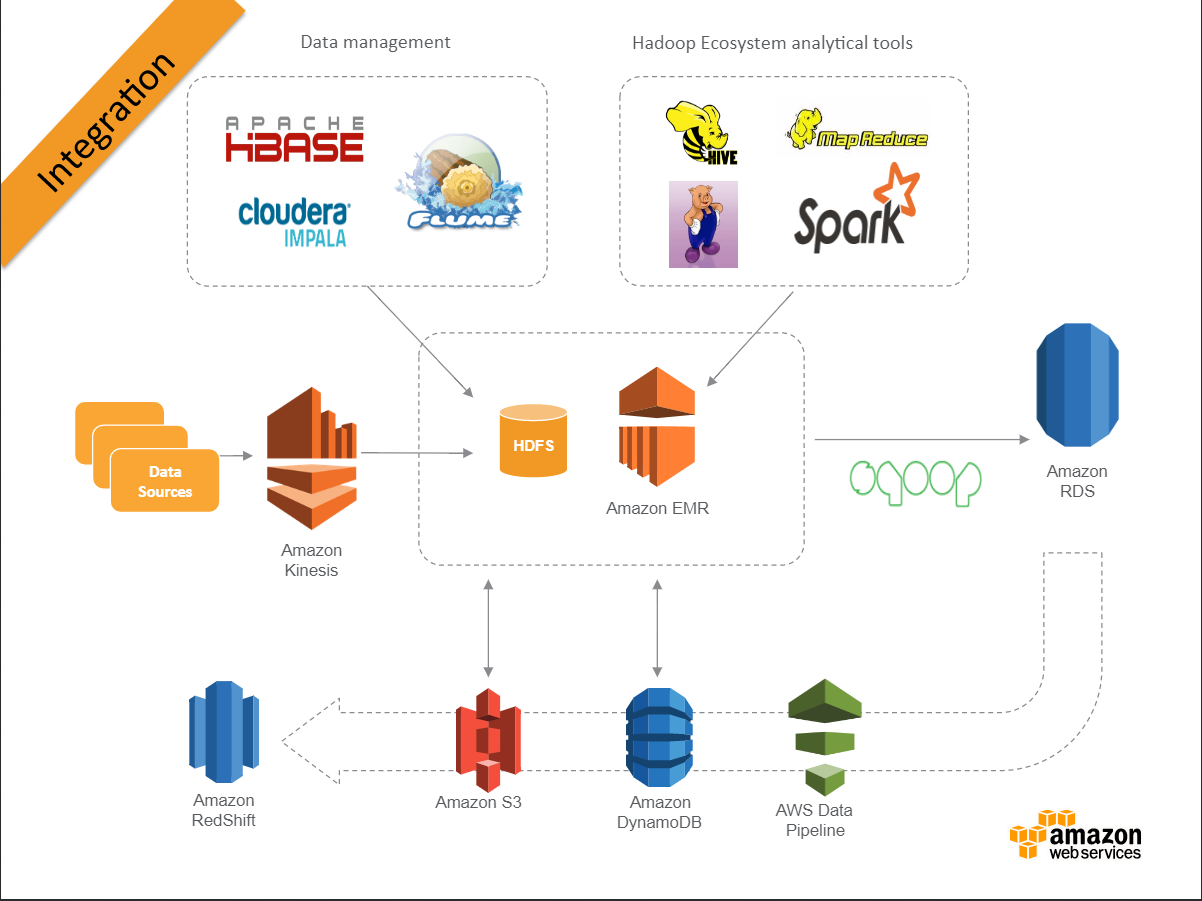
資料可以從s3、kinesis 餵入EMR,經過hadoop or spark處理後,在把output輸出在DB or S3,Data Pipeline可以設定排程來執行EMR的work
首先點進AWS EMR的service,點擊Create cluster來到新增EMR畫面
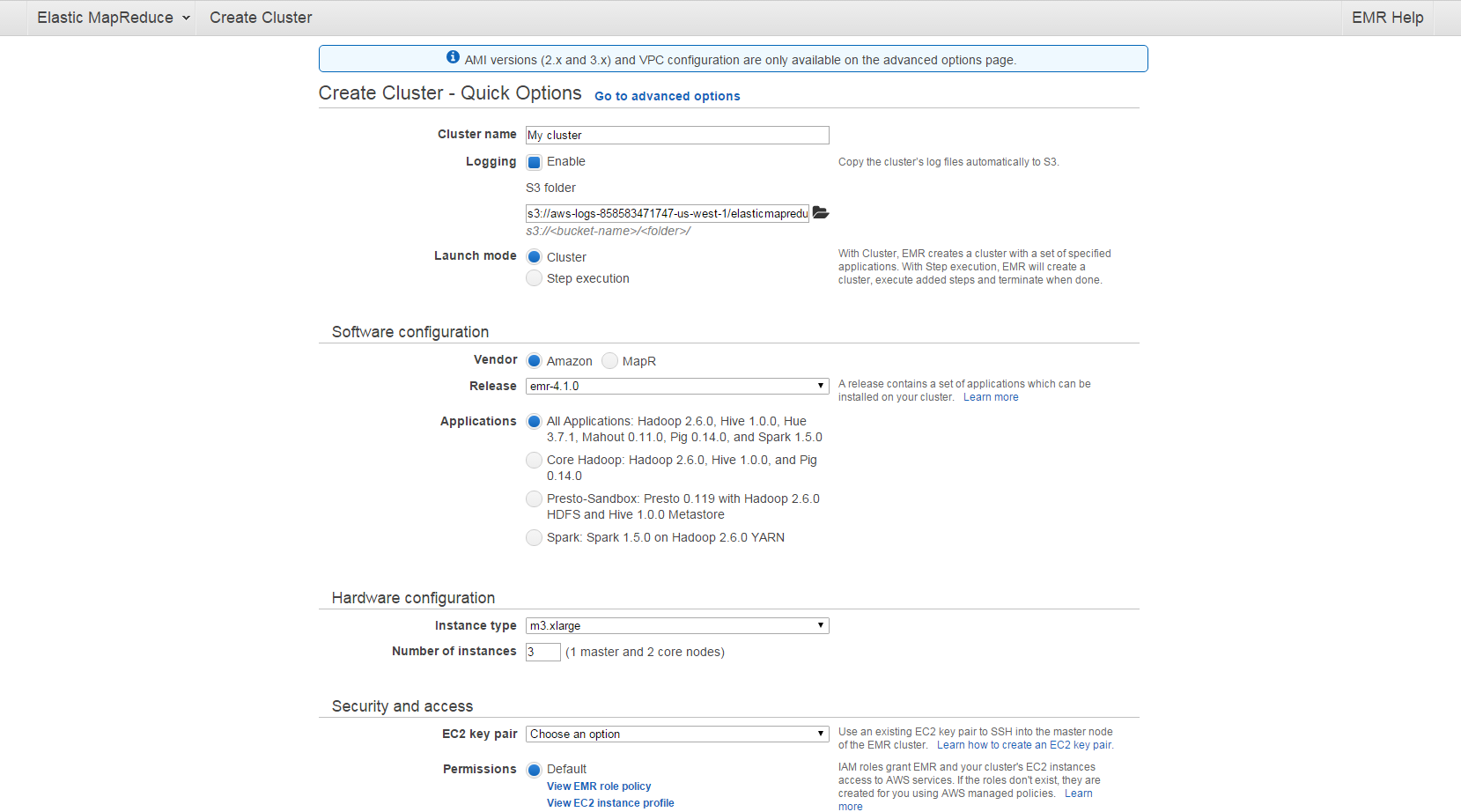
選擇上方的Go to advanced options,可以進行比較客製化的設定,不需要裝一些自己用不到的套件
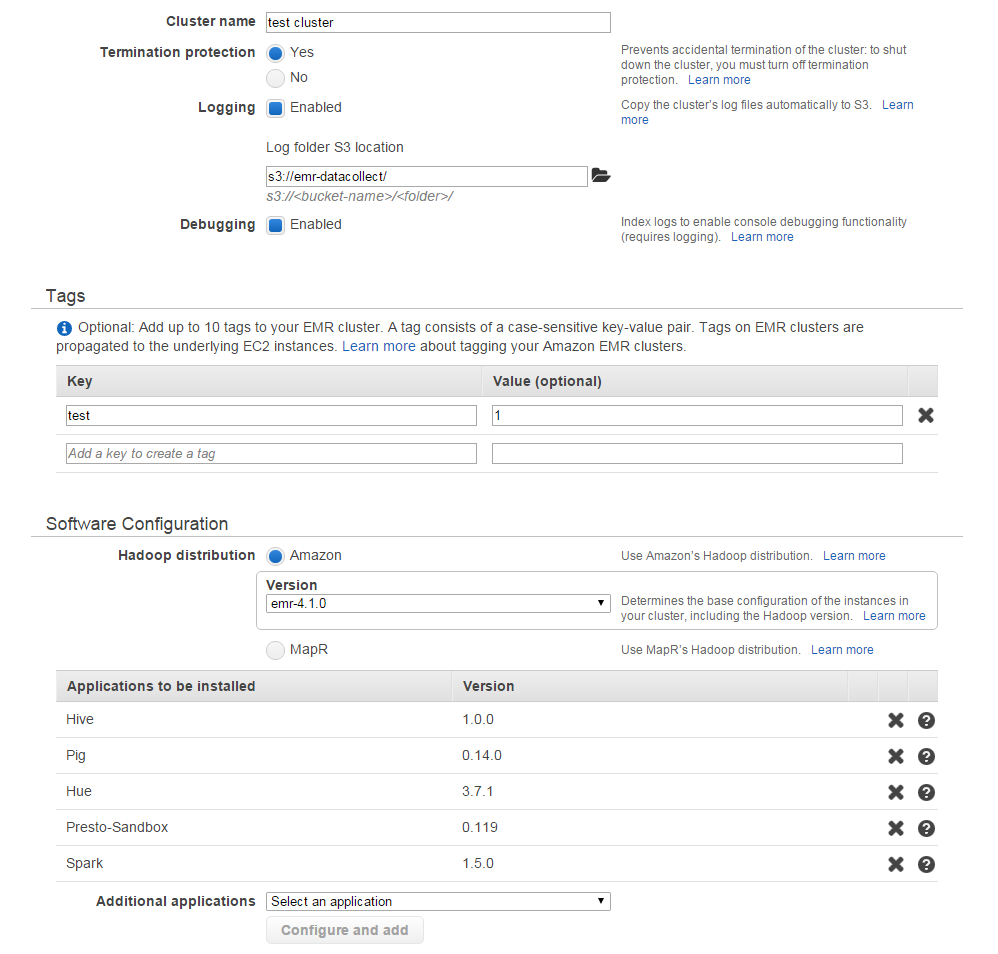
– 輸入自己的cluster name
– 指定一個s3的bucket位置存放HDFS
– 輸入自己EMR cluster的TAG(optional)
– 配置自己要裝得套件,我這邊是要用spark就沒選擇hadoop,其他還有hive、pig、hue、presto
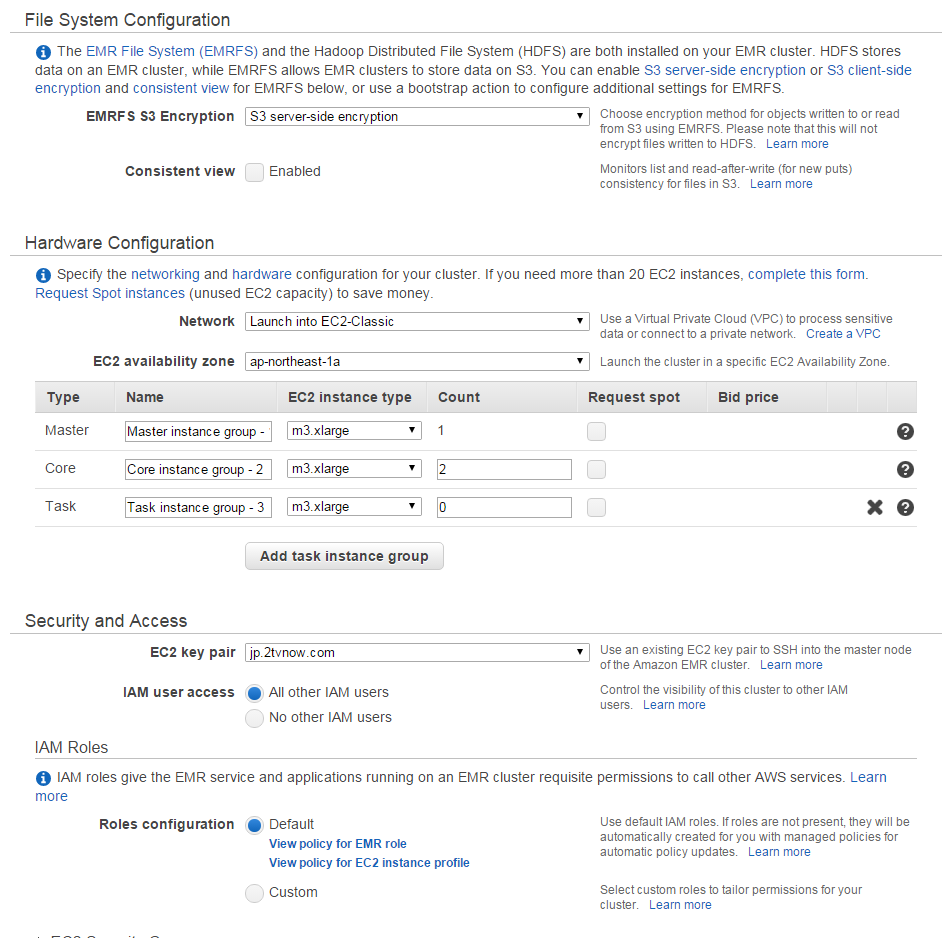
– EMRFS負責將資料存進S3,這邊設定在server端加密
– 網路選擇classic就好(vpc等研究透徹在設)
– 使用default的一個master node兩個core node,master node是不能刪減的,之後要scaling透過增減core跟task node來實現,core跟task的差別在於,core還負責把資料存到HDFS,而task只負責計算
– 設定key pair
– 最後記得account要把EMR role的權限打開,不然無法進行配置
剩下的steps可以設定spark要submit的jar file,這邊先不設定,直接按create cluster就建立完成
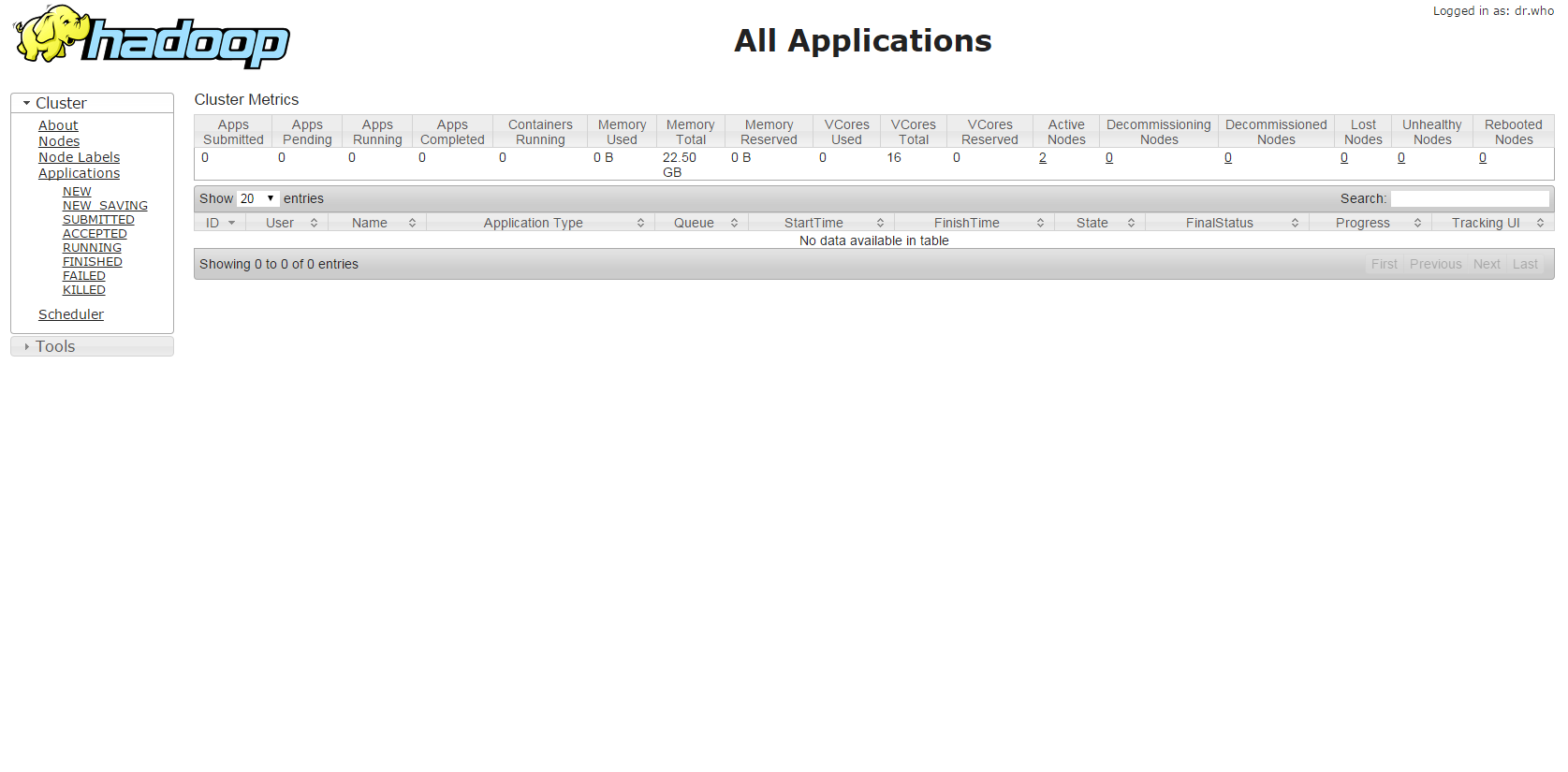
等一段時間node建立完後,SSH進入master node的DNS,username是”hadoop”,看到以下畫面,就可以開始跑經典的word count了!
可愛的登入介面XD
最後,一個分散式系統都要有個web view,EMR為了隱私問題,需要以master node為跳板,才能連進spark後台
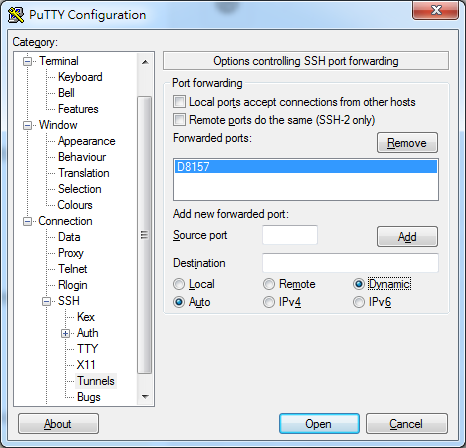
到putty的ssh->Auth->tunnel,隨意新增一個沒使用的port,這邊跟官方教學一樣輸入8157,並選擇dynamic跟auto的選項,連進去跳板server就開啟了
再來網頁要打開需要設定proxy,下載foxyproxy
http://foxyproxy.mozdev.org/downloads.html
然後新增一個檔案叫foxyproxy-settings.xml,import進foxyproxy
<?xml version="1.0" encoding="UTF-8"?>
<foxyproxy>
<proxies>
<proxy name="emr-socks-proxy" id="2322596116" notes="" fromSubscription="false" enabled="true" mode="manual" selectedTabIndex="2" lastresort="false" animatedIcons="true" includeInCycle="true" color="#0055E5" proxyDNS="true" noInternalIPs="false" autoconfMode="pac" clearCacheBeforeUse="false" disableCache="false" clearCookiesBeforeUse="false" rejectCookies="false">
<matches>
<match enabled="true" name="*ec2*.amazonaws.com*" pattern="*ec2*.amazonaws.com*" isRegEx="false" isBlackList="false" isMultiLine="false" caseSensitive="false" fromSubscription="false" />
<match enabled="true" name="*ec2*.compute*" pattern="*ec2*.compute*" isRegEx="false" isBlackList="false" isMultiLine="false" caseSensitive="false" fromSubscription="false" />
<match enabled="true" name="10.*" pattern="http://10.*" isRegEx="false" isBlackList="false" isMultiLine="false" caseSensitive="false" fromSubscription="false" />
</matches>
<manualconf host="localhost" port="8157" socksversion="5" isSocks="true" username="" password="" domain="" />
</proxy>
</proxies>
</foxyproxy>
下面是foxyproxy import的简单教學
1. Click on the FoxyProxy icon in the toolbar and select Options.
2. Click Import/Export.
3. Click Choose File, select foxyproxy-settings.xml, and click Open.
4. In the Import FoxyProxy Settings dialog, click Add.
5. At the top of the page, for Proxy mode, choose Use proxies based on their pre-defined patterns and priorities
連進去啦 http://master DNS:8088/cluster
之後要看server log都在這