 QQ咨询
QQ咨询
AWS各种场景下如何将MySQL数据库迁移到Amazon Aurora
AWS DMS 数据库迁移十问
自从2018年8月8日,AWS Database Migration Service 和 AWS Schema Conversion Tool 在 AWS 中国(北京)区域和 AWS 中国(宁夏)区域推出以来,已有3 个多月的时间,在这段时间里已经有非常多的 AWS 客户及合作伙伴,在 AWS 中国(北京)区域和 AWS 中国(宁夏)区域 试用了该服务或已正式投入生产。根据大家在使用过程中遇到的一些问题及优化建议进行了总结,并分享如下。
(一) 常见迁移环境
AWS DMS 是一项托管服务,可轻松迁移关系数据库、数据仓库、NoSQL 数据库及其他类型的数据存储。可以在本地实例之间或云与本地设置的组合之间使用 AWS DMS 将数据迁移到 AWS 云中,广泛支持将各种开源数据库、商业数据库以及托管的 RDS作为数据迁移的源与目标,总之需要源与目标任何一端在 AWS 云端即可,AWS DMS 架构参考如下:
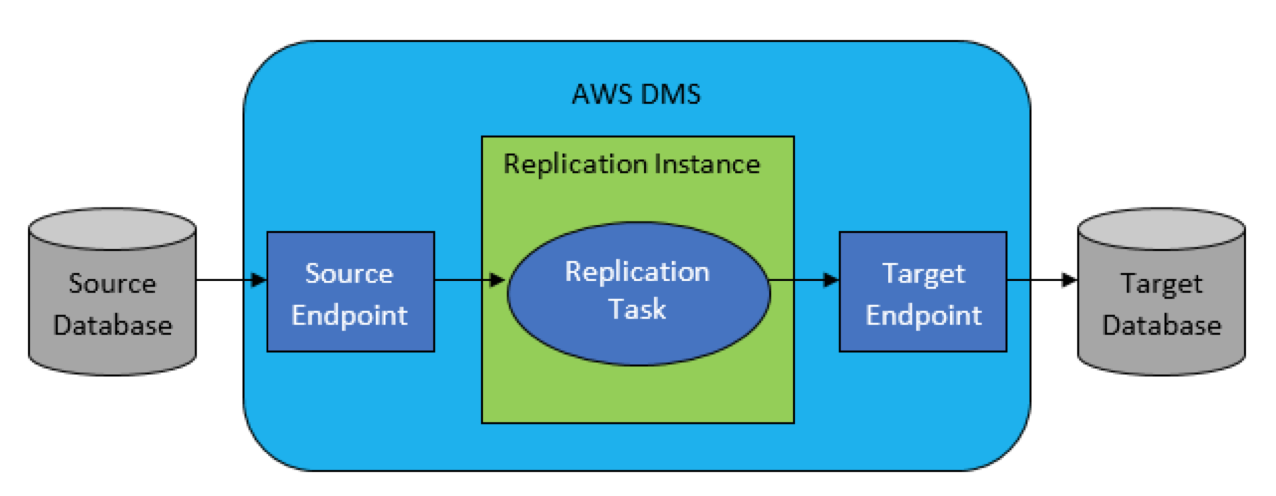
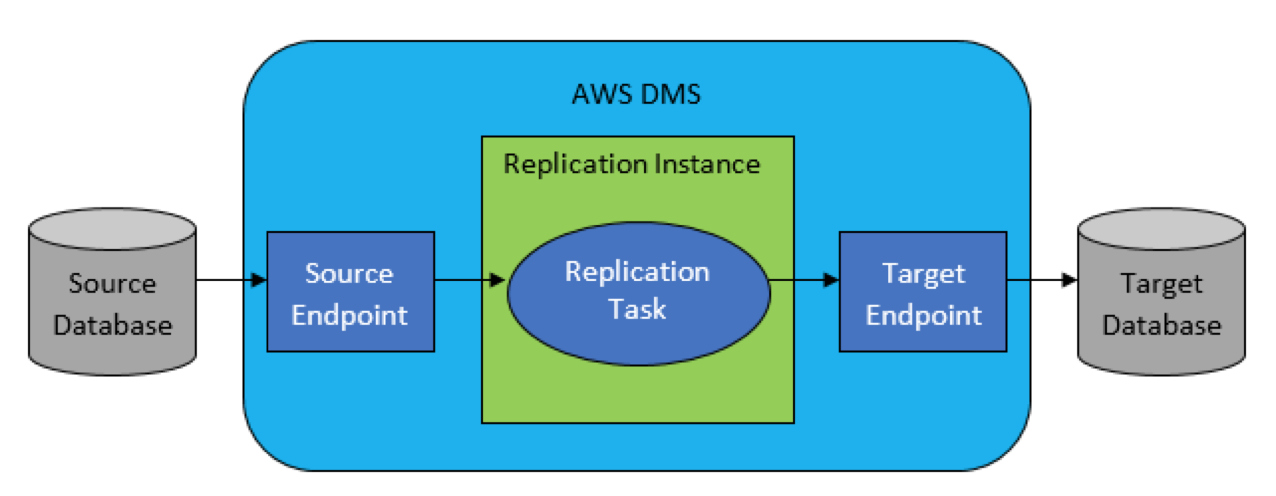
运行 AWS DMS数据迁移的完整过程如下:
1) 确定用于数据迁移的网络环境;
2) 确定数据迁移的源和目标数据库;
3) 创建 AWS DMS 复制实例;
4) 配置源和目标数据库连接信息的终端节点;
5) 创建复制任务,指定要迁移的数据表和转换规则;
6) 迁移后的数据验证;
在AWS DMS 数据迁移过程中,网络环境至关重要,是整个数据库迁移项目成功的关键,针对不同的迁移场景,对几种常见的网络环境说明如下:
1) 源与目标在同一 VPC 内
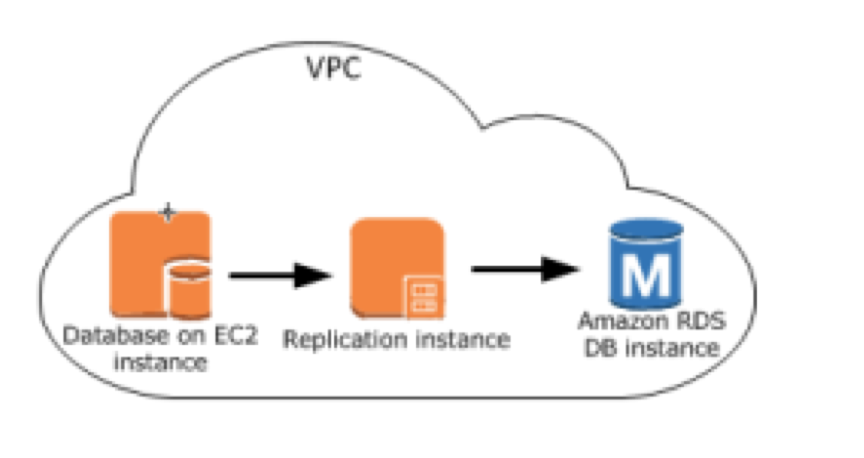
2) 源与目标在不同 VPC
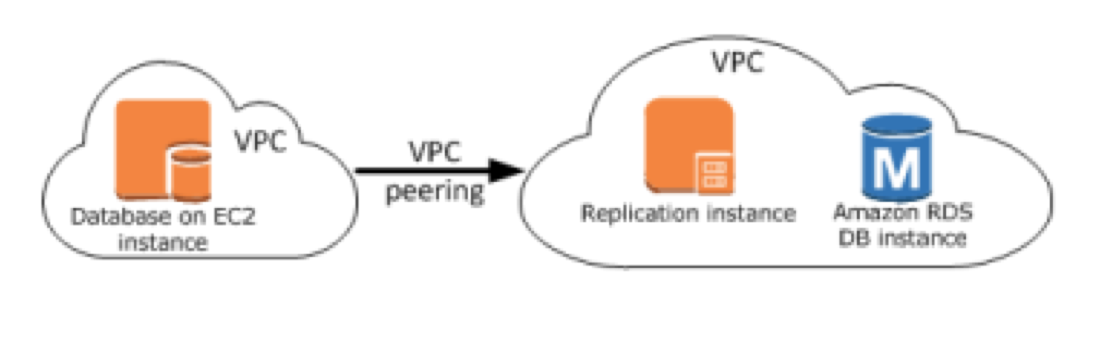
3) 通过专线或 VPN 从本地数据中心到云端
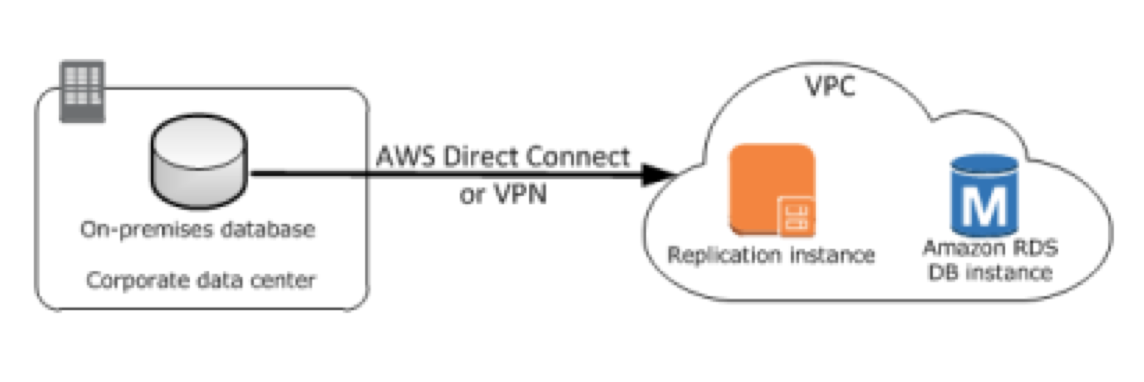
4) 通过互联网从本地数据中心到云端
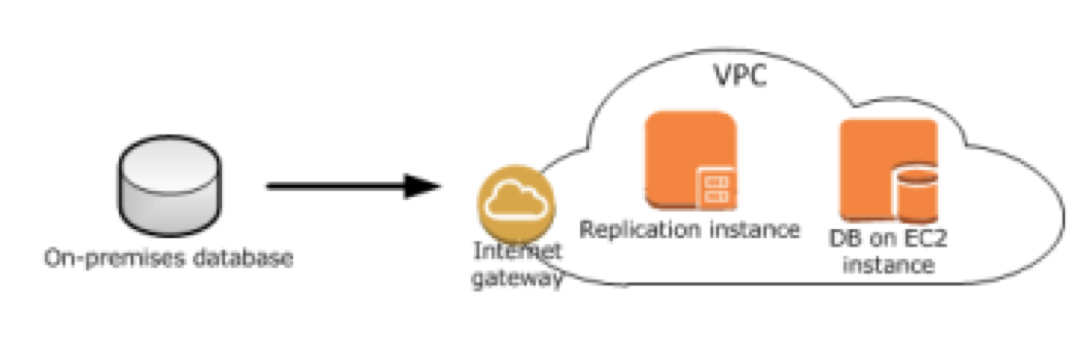
对于以上 4 类网络环境,第 1、2 类情况都是在云端,不存在网络稳定性问题,像跨帐号、跨 VPC 的都可以直接采用 VPC 的对等连接。
在实际的迁移案例中,往往大家遇到的都是第 3、4 类情况,在测试阶段大都是采用VPN或是互联网。由于中国互联网的环境复杂,数据量稍大点,测试过程中就可能遭遇各种莫名其妙的问题。第 3、4 类情况,如果是长期运行的 DMS CDC 持续数据迁移任务,请尽量选择专线。如果是一次性数据迁移,网络环境不稳定、数据量大,建议采用先导出 CSV 到 S3, 再将 S3 作为 DMS 的源。
(二) 常见问题及优化方法
AWS DMS 在数据库的迁移过程中复制实例都是通过 ODBC 接口与源、目标数据库通讯来实现数据的最终一致,Redshift 为提高性能采用的方法比较特殊,是先到 S3再 COPY 到 Redshift ,常见问题及优化方法汇总:
1) 如何设置复制实例的子网组?
子网组是复制实例驻留的地方,请参照上面 4 类网络环境去设置。如果是访问位于互联网上的数据库,建议用公有子网或带NAT的私有子网。如果都在云端,建议与目标数据库位于相同的子网。
2) 为什么目标端数据库表中数据中文内容都显示成乱码或问号?
中文乱码属于常见问题,请检查源与目标端的数据库字符集是否一致。针对不同的数据库有不同的设置方法,请在迁移前优化确认此项设置。只要有中文乱码问题数据验证都无法通过。
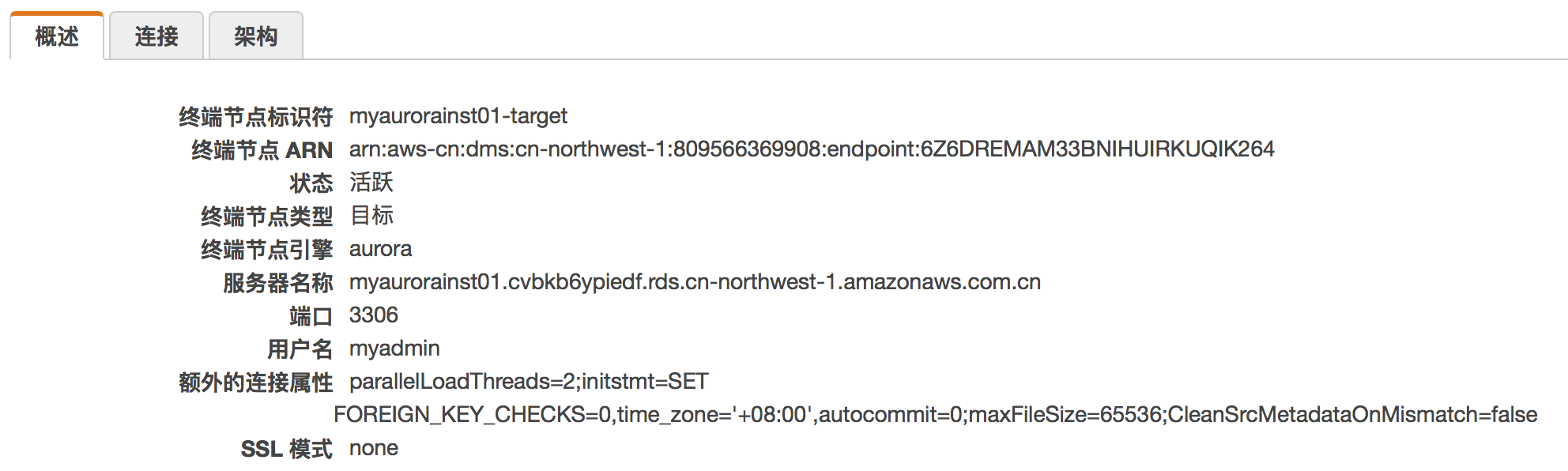
3) 如何正确设置源与目标的额外属性?
额外属性主要用于控制复制实例在源与目标的行为,针对不同的数据库,源与目标的额外属性内容不一,但设置方法雷同,详细请参见官方文档中心的说明,主要规则说明如下:
a) 具有多个额外属性,用分号分隔;
b) 单个属性多个值时,用逗号分隔;
如下是将 MySQL 数据库作为源,Aurora 作为目标时的额外性调置参考:
eventsPollInterval=60;initstmt=SET time_zone=’+08:00′,autocommit=1;CleanSrcMetadataOnMismatch=false
parallelLoadThreads=2;initstmt=SET FOREIGN_KEY_CHECKS=0,time_zone=’+08:00′,autocommit=0;maxFileSize=65536;CleanSrcMetadataOnMismatch=false
4) 如何启用验证与日志记录?
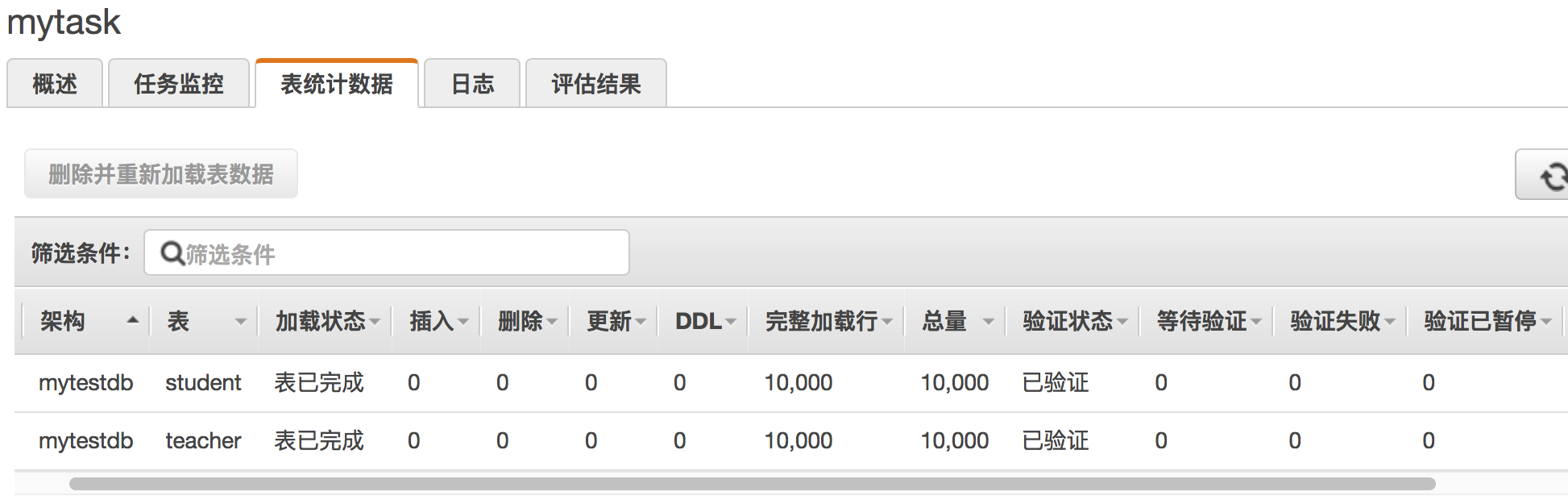
在创建任务的时候选择启用验证与日志记录。
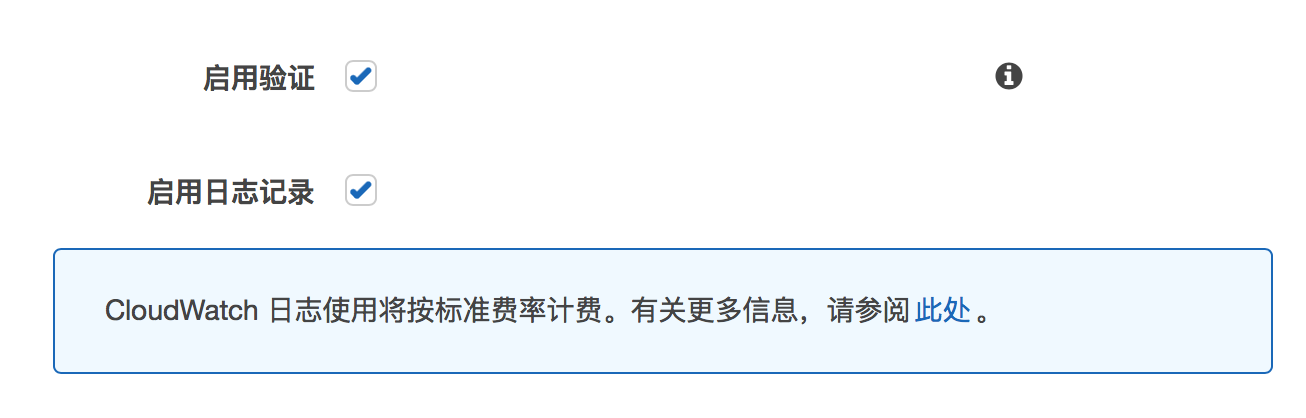
通过查询表统计数据,能看到验证状态。
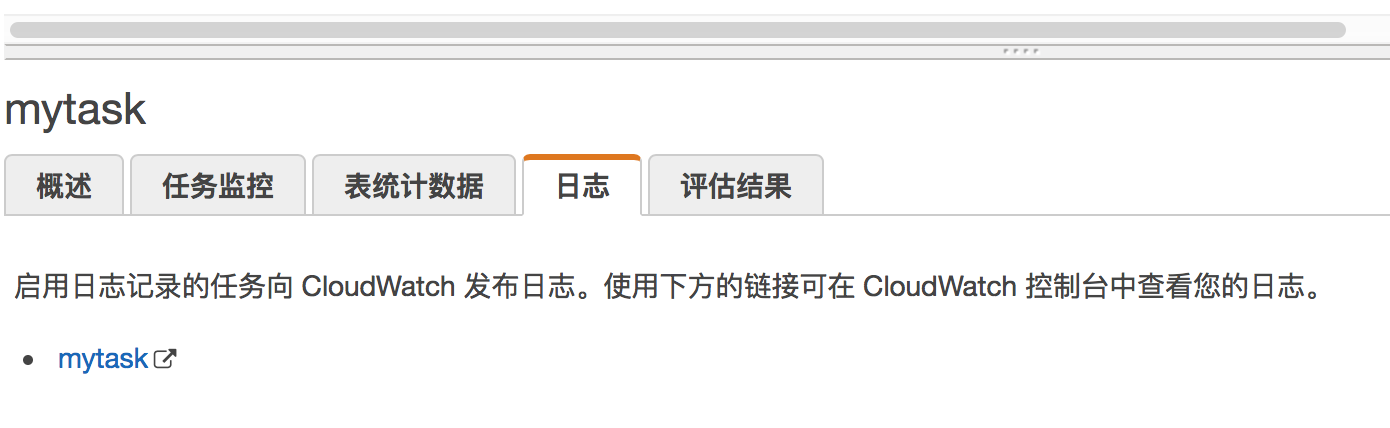
启用日志记录,直接点击能到 CloudWatch 查看日志。
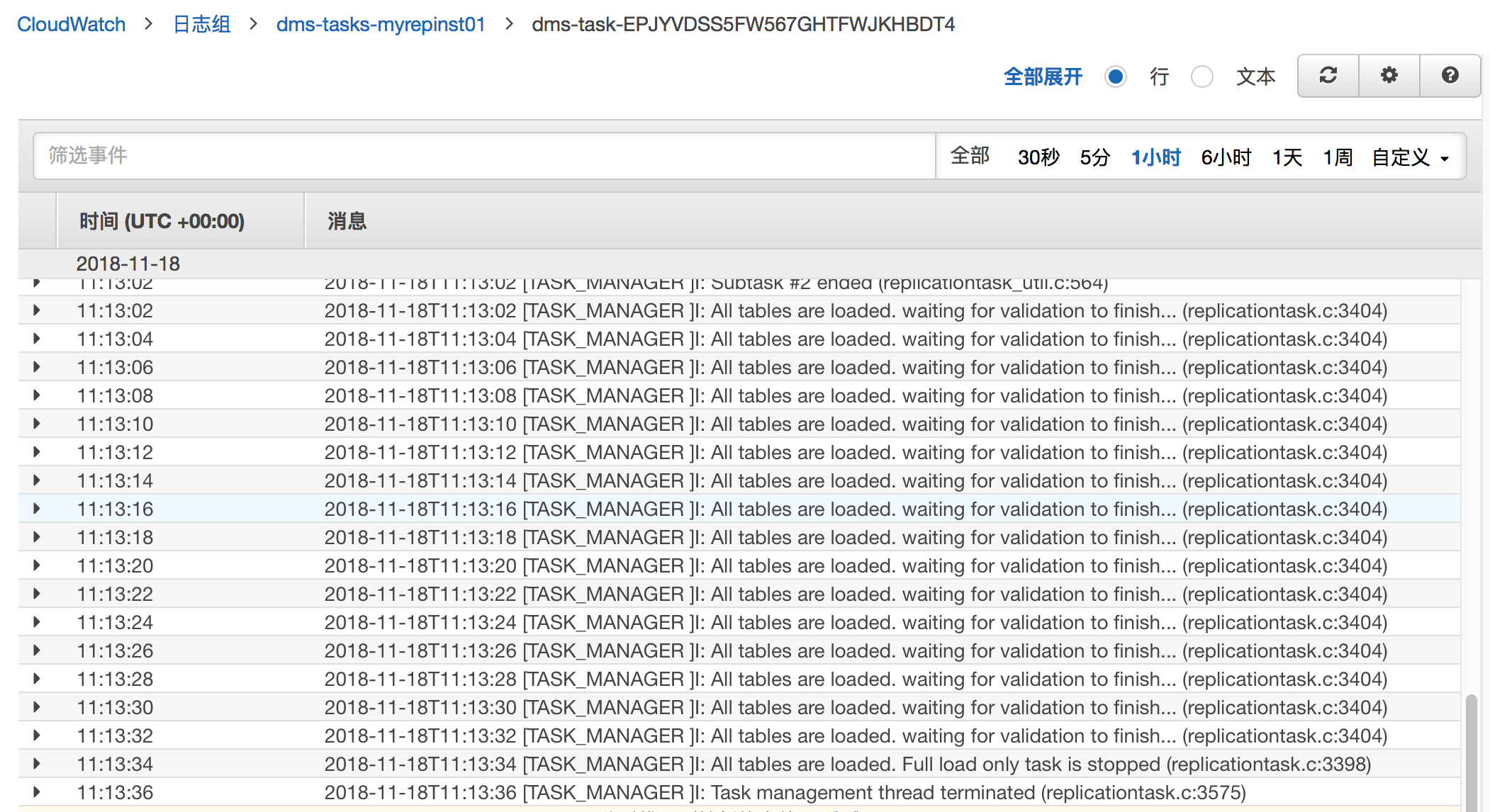
即使前面验证都正常,也要养成查看日志记录的习惯,只有日志里面才会详细记载 DMS 的运行过程,这是后期 DMS Troubleshooting 与 Performance Tuning 的主要信息来源。
5) 为什么总是有一些表没数据或是迁移不成功?
请先检查日志,确认日志里面是否有主外键冲突的提示?如果有请参考额外属性禁用主、外键约束检查,如果已经设置请确认是否生效或设置正确。
6) 为什么有些表的完整加载行比总量还多?
这种现象可能是因为重复加载导致,不稳定的网络有可能会触发DMS的重复加载。建议先检查日志,再找到对应的表,如果有重复加载在日志里面会有显示。尤其像Redshift的迁移机制很容易产生这种问题。
7) 为什么“完整加载行”与“总量”一致,但数据验证还是未通过?
仅凭记录数是无法保证数据的一致性,AWS DMS 采用一种 HASH 算法来验证迁移后源与目标数据内容的一致性,如果记录数一致,但验证未通过,绝大多数是因为字符集与时区问题导致的字段内容不一致,设置正确的额外属性并重新加载数据。
8) 为什么 DMS 实例运行一段时间后任务就挂起?
先通过 ping 检查 DMS 实例是否通讯正常,再检查复制实例的运行状态,确保 DMS 实例本身运行正常,最后去检查 DMS 运行日志,结合对应的时间点来看监控数据。如果这些数据都正常,再去检查任务的设置是否合理,单个任务理论上能支持60000 张表,但这与所采用的 DMS 实例类型有关,如果换更大实例也不能解决 DMS 实例需要的资源,建议拆分成多个实例。
9) 如何提高大型表的迁移性能?
DMS 在迁移的过程,数据导出操作会有共享锁,如果在单个任务中迁移大表,会增大 DMS 导出操作持有共享锁的时间,大型表建议根据筛选条件进行任务分解。
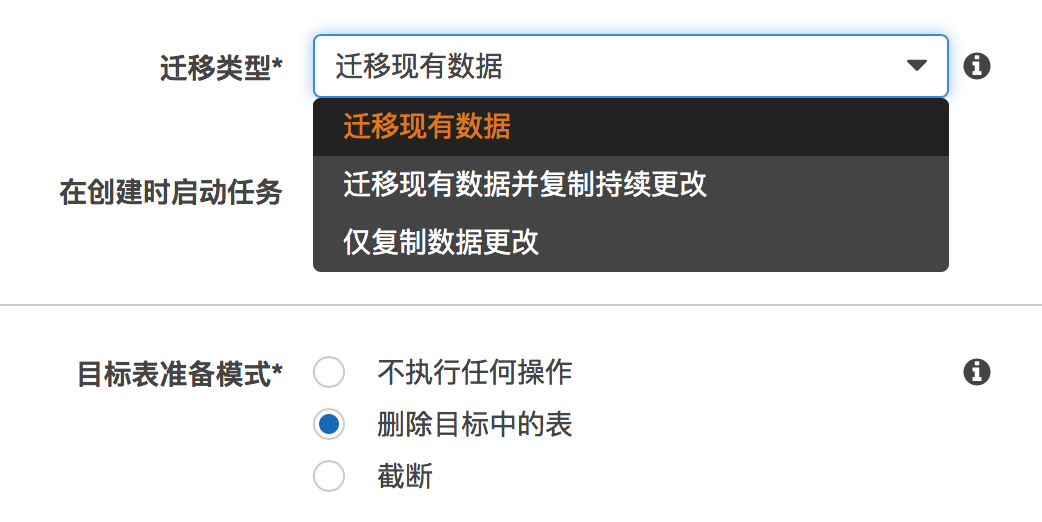
10) 我应该选择什么样的迁移类型?
根据不同的业务场景,如果是可以停机的一次性数据迁移,建议选择“迁移现有数据”,如果迁移过程中要避免停机或不影响业务,建议选择“迁移现有数据并复制持续更改”,如果只是需要复制增量数据,建议选择“仅复制数据更改”。
(三) 总结及参考资源
AWS DMS 目前主要定位于数据库迁移,并支持一部分数据源的 CDC 功能,支持与其他的 AWS 服务集成,目前已经支持 S3 、CloudFormation ,可以实现更多的扩展功能。像 AWS RDS 本身并不提供 BINLOG 分析功能,可以结合 AWS DMS CDC 的功能,对要分析的源库启用 CDC 复制,并将 S3 作为目标,变更的数据都会以 CSV 格式自动复制到 S3 桶里,通过直接分析 CSV 文件,实现对数据库的日志分析。AWS DMS 不支持基于时间的任务调度,可以结合 CloudFormation 自动化与 Lambda 调度复制任务。
对于将 Amazon Aurora, Amazon Redshift 或 Amazon DynamoDB 作为目标的迁移任务,并且使用单 AZ 的t2.micro, t2.small, t2.medium, t2.large和c4.large五种实例类型,将提供 6 个月的免费使用时间用于数据迁移。
AWS DMS 除了具备数据库迁移能力外,更像是传统企业端的 CDC 增量数据库复制软件,提供企业级数据库整合、数据分发功能,并能向数据仓库提供增量数据,后期我们将期待更多的 AWS DMS 特性发布。
[参考资源]
AWS各种场景下如何将MySQL数据库迁移到Amazon Aurora
随着Amazon Aurora数据库被客户从认识到认可,越来越多的企业客户在完成功能和性能的验证以后,会考虑把他们在生产环境中运行的MySQL数据库迁移到Amazon Aurora数据库上。本文描述了在各种不同的场景下,如何把MySQL数据库的数据迁移到Amazon Aurora里。以下内容的描述,如果没有特别说明,都是基于AWS的us-west-2区进行介绍,并且按照从简单到复杂的顺序对各种场景进行描述。
场景一:Amazon MySQL RDS迁移到Amazon Aurora并有停机时间
如果客户正在使用Amazon MySQL RDS,并且有足够的停机迁移的时间窗口的话,那么可以通过RDS快照的方式进行迁移。具体操作过程如下:
1)停止应用程序对源数据库的写入操作。
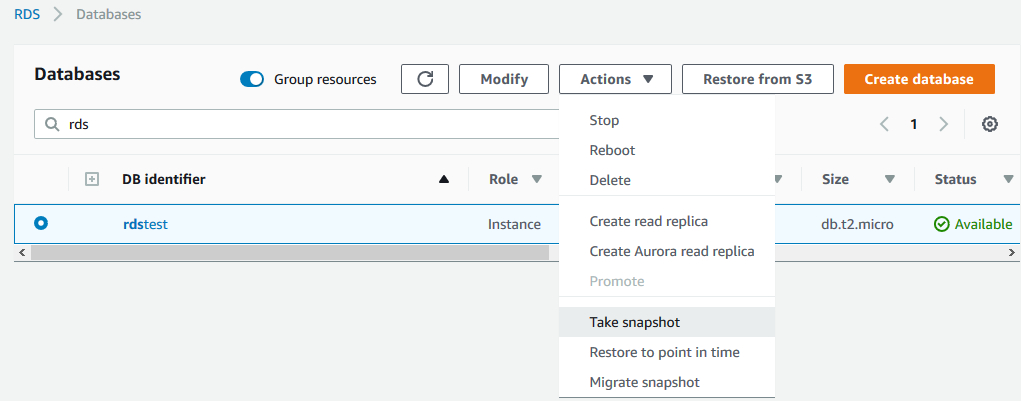
2)对源数据库创建快照,可以使用图形界面进行操作,选中要迁移的数据库实例,Actions下来菜单中选择Take snapshot,如下图所示:
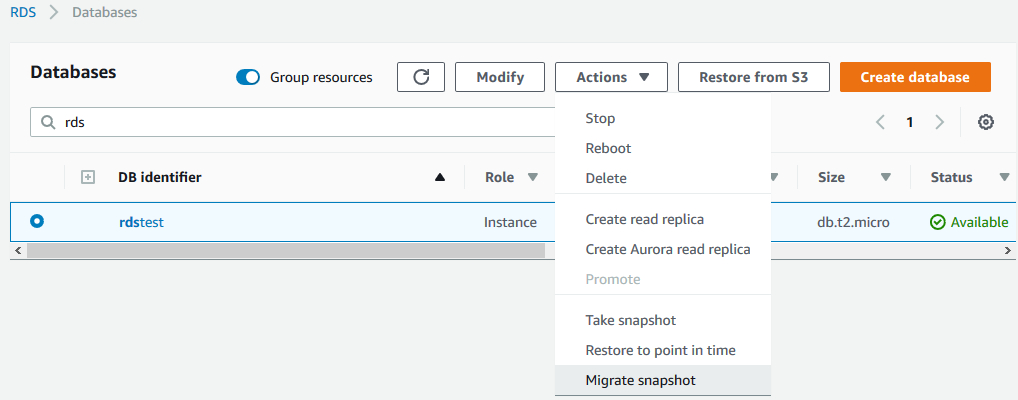
3)根据快照恢复出一个Aurora数据库。可以使用图形界面操作,在数据库列表中,选中之前创建快照的数据库实例,Actions下来列表中选择Migrate snapshot,如下图所示。
在随后显示的页面中,输入Aurora数据库的相关信息即可,包括指定一个新的Aurora数据库实例名称,网络配置等,这部分内容与直接创建一个新的Aurora数据库是完全一致的。
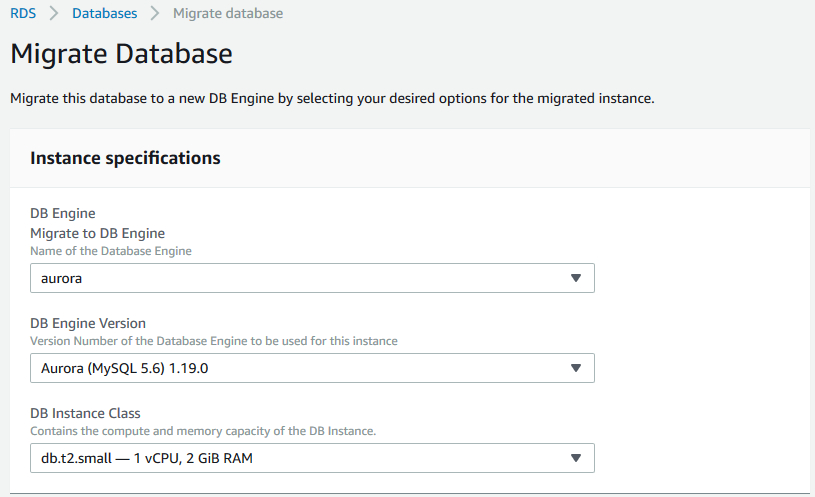
4)等到Aurora数据库创建好以后,就可以修改应用程序的连接字符串,指向Aurora,从而投入使用了。
场景二:Amazon MySQL RDS迁移到Amazon Aurora并要求最小停机时间
如果客户正在使用Amazon MySQL RDS,并且没有足够的停机时间来通过snapshot的方式进行迁移的话,那么可以通过为MySQL RDS创建Aurora读副本的方式进行迁移。具体操作过程如下:
1)在控制台界面上选中要迁移的MySQL RDS数据库,在Actions下拉菜单中选择Create Aurora read replica,如下图所示。
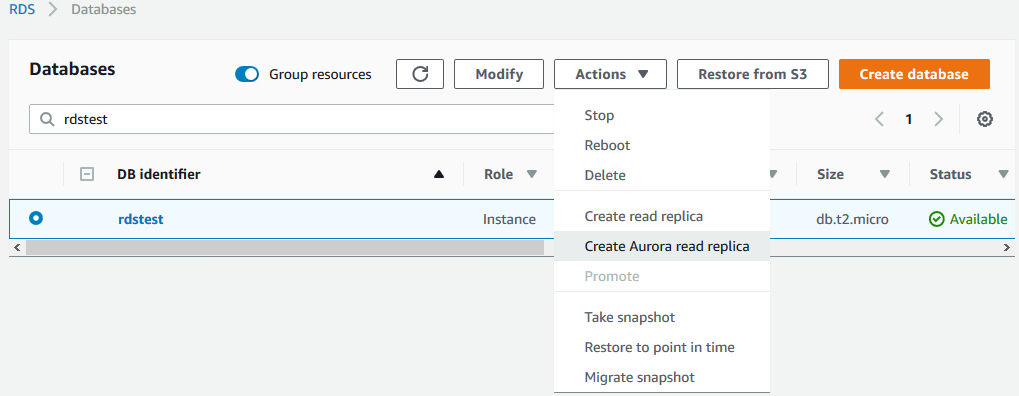
2)在创建Aurora副本的界面上输入相关的信息,其过程与创建一个新的Aurora数据库类似。
在创建Aurora读副本的过程中,源MySQL RDS数据库可以仍然被业务系统访问并使用。在读副本创建完毕以后,该副本的内容会自动与MySQL RDS主库保持数据同步。
在确定要进行切换之前(通常都是在业务低谷的时间段),关闭应用程序,从而停止应用程序对主库的写入操作,并登陆到Aurora里执行下面的命令来判断Aurora读副本是否与主库保持同步了:
show slave status \G
检查输出里的Seconds_Behind_Master字段的值,如果为0则表示Aurora读副本已经与MySQL RDS主库保持同步了。否则继续等待,直到该字段为0为止。然后选择Aurora只读副本,在Actions下拉菜单中选择Promote选项。
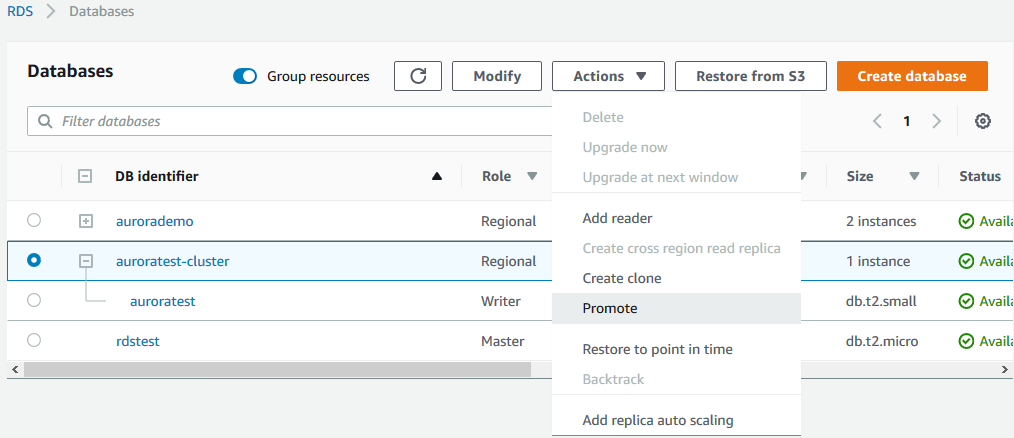
在弹出的界面中,选择Promote Read Replica按钮,从而把Aurora只读副本提升为主库。
一旦完成主从切换,再次登陆到Aurora数据库,执行show slave status的时候,会发现已经没有输出信息了。这也就说明Aurora数据库已经不再是一个只读副本,而变成了一个完全独立的数据库。
修改应用程序的数据库连接字符串,使其指向Aurora数据库,并启动应用程序,从而开始在生产环境中使用Aurora数据库。
场景三:自建MySQL数据库迁移到Amazon Aurora并有足够的停机时间
如果客户没有使用Amazon MySQL RDS,而是在EC2虚拟机里,或者本地数据中心的服务器上,由客户自己部署安装的MySQL数据库,需要迁移到Aurora数据库,同时也有足够的停机迁移时间窗口,那么可以使用备份恢复的方式,进行迁移。其操作过程如下:
1)到Percona官方网站上下载XtraBackup工具,这里下载4.1版本(https://www.percona.com/downloads/Percona-XtraBackup-2.4/LATEST/),如下所示:
tar -xzvf percona-xtrabackup-2.4.1-Linux-x86_64.tar.gz
2)执行Percona XtraBackup命令,创建备份。比如下面的例子:
innobackupex –user=root –password=<your password> –database=myaurora –stream=tar ~/s3-restore/backup2 | split -d –bytes=51200000 – ~/s3-restore/backup.tar
3)把数据库备份(本例中是tar开头的文件,比如backup.tar00,其中包含了xtrabackup生成的数据库备份文件)上传到S3,如果是在本地数据中心生成的备份,并且尺寸特别大的话,可以使用AWS Snowball服务进行上传。具体参考:https://aws.amazon.com/cn/snowball/
4)把备份从S3恢复到Amazon Aurora数据库里。如下图所示:
a.在RDS控制台上选择Restore from S3按钮

b.选择Aurora引擎
c.指定备份的相关信息,如下图所示
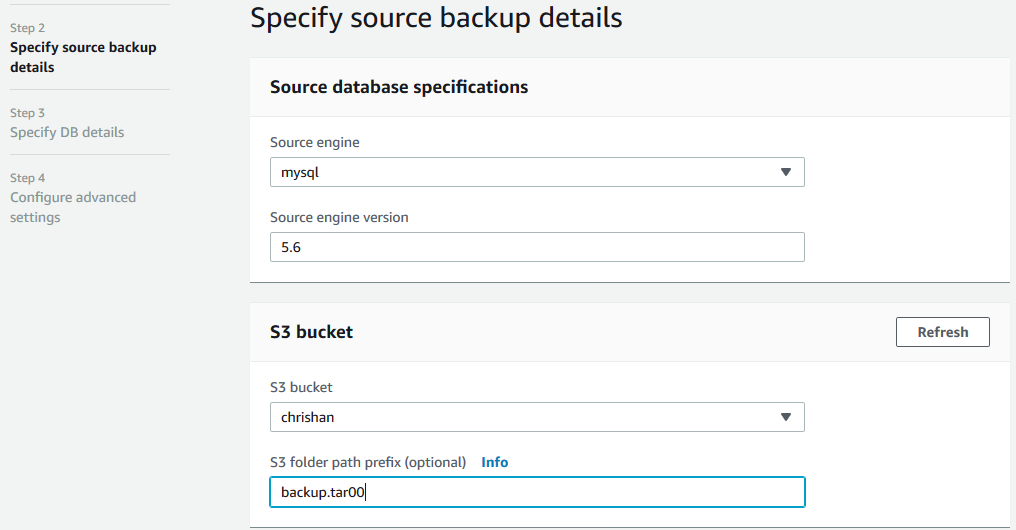
d.在数据库的配置的相关页面上,输入Aurora数据库的信息,比如数据库的名称,管理员名称与密码等,这一步与正常创建Aurora数据库的过程是一样的。
5)当Aurora数据库恢复完成以后,就可以投入生产使用了。
场景四:自建MySQL数据库迁移到Amazon Aurora并要求最小停机时间
如果客户是在EC2或者本地数据中心自己部署的MySQL数据库,希望迁移到Amazon Aurora数据库,同时没有足够的停机时间来通过备份恢复的方式完成整个迁移。这种场景相对比较复杂,通常可以使用两种方式来进行最小时间停机的迁移。
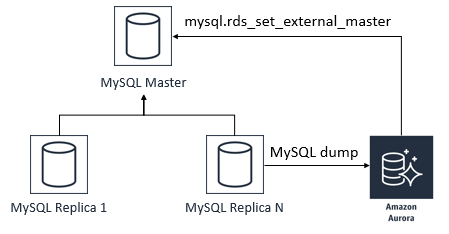
方式1:通过构建MySQL主从副本的方式完成迁移,整个流程如下所示:
1)创建Aurora从库(即读副本),通过binlog与MySQL主库保持同步,如下图所示。
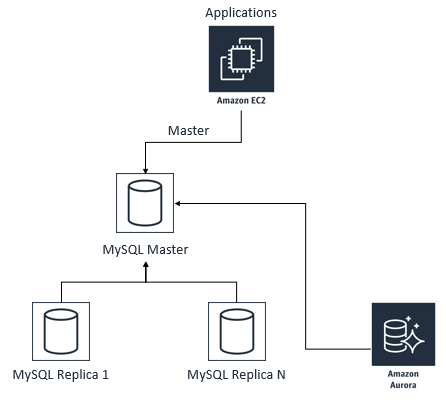
2)MySQL主,Aurora从的关系建立起来以后,持续进行数据同步,如下图所示。在这个阶段,Aurora数据库只能进行读操作,不能进行写操作,可以把Aurora的read_only参数设置为1强制只读,或者也可以保持0,而是从应用程序端进行控制,禁止其在Aurora数据库里进行写操作。
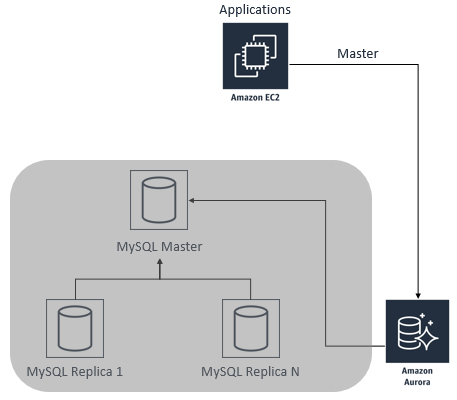
3)当需要进行切换的时候,也就是业务低谷的时候,停止应用程序在源MySQL数据库里的写入操作,然后等到Aurora从库的数据与MySQL主库的数据完全一致以后,修改应用程序的连接字符串,使其指向Aurora从库,使得Aurora数据库变为主要的写入数据库(如果你之前把Aurora数据库的read_only设置为了1,则需要把其改回到0,从而允许写入Aurora数据库)。而原来的MySQL数据库则可以被销毁。该阶段如下图所示。
具体操作过程如下:
1)使用xtrabackup对主库进行备份,并指定–slave-info,从而生成日志点的位置信息,如下例所示:
innobackupex –user=root –password=<your password> –database=myaurora –slave-info –stream=tar ~/s3-restore/backup2 | split -d –bytes=51200000 – ~/backup.tar
2)提取tar开头的文件(比如backup.tar00)里的xtrabackup_binlog_info文件,其中存放了日志点的信息。
3)把备份(这里是tar开头的文件,比如backup.tar00)上传到S3,并按照场景三所示的方式恢复出一个Aurora数据库。
4)进入Aurora数据库,并执行下面的存储过程,从而把Aurora数据库配置为MySQL的副本。注意这里的mysql-bin.000001和1024就是从xtrabackup_binlog_info文件中找出来的、备份的时候的日志点的信息。
5)一旦Aurora数据库与主库建立起了主从复制的关系以后,等到业务低谷的时候,停止应用程序对MySQL数据库的写入操作,并等到Aurora与MySQL完全一致以后,把应用程序的数据库连接字符串改为Aurora数据库即可。
方式2:通过使用AWS DMS服务完成迁移,整个流程如下所示:
AWS Database Migration Service(DMS)服务可以帮助客户在最小停机时间的情况下, 采用在源库上捕获变化数据,并在目标库上应用变化数据的形式,进行数据库的整体迁移。DMS不仅可以进行相同数据库引擎的迁移,同时还支持不同数据库引擎之间的迁移。不过DMS只能迁移数据本身,其他数据库对象,比如存储过程等,是不能迁移的。需要手工在目标数据库里创建。有关DMS的详细信息可以参考:https://aws.amazon.com/dms/。
具体操作过程如下所示:
1)创建复制实例。复制实例的目的在于管理DMS在运行复制过程中的一些元数据。创建过程如下图所示。
在DMS的主页上,选择Replication instances,然后在右边点击Create replication instance按钮。在显示的界面上输入DMS实例相关的一些信息,比如实例名称,实例大小等。需要注意的是,如果需要传输的数据量比较大,同时源数据库上有较大的工作压力的话,应该选择较大的机型。具体细节可以参考:https://docs.aws.amazon.com/dms/latest/userguide/CHAP_ReplicationInstance.html#CHAP_ReplicationInstance.Creating
2)创建source endpoint,指向源数据库。
在右边选择Endpoints,点击Create endpoint按钮。
选择endpoint type为Source endpoint,并指定源数据库的信息,如下所示:
点击创建endpoint按钮从而创建source endpoint。
创建了source endpoint以后,我们可以进行连接测试:
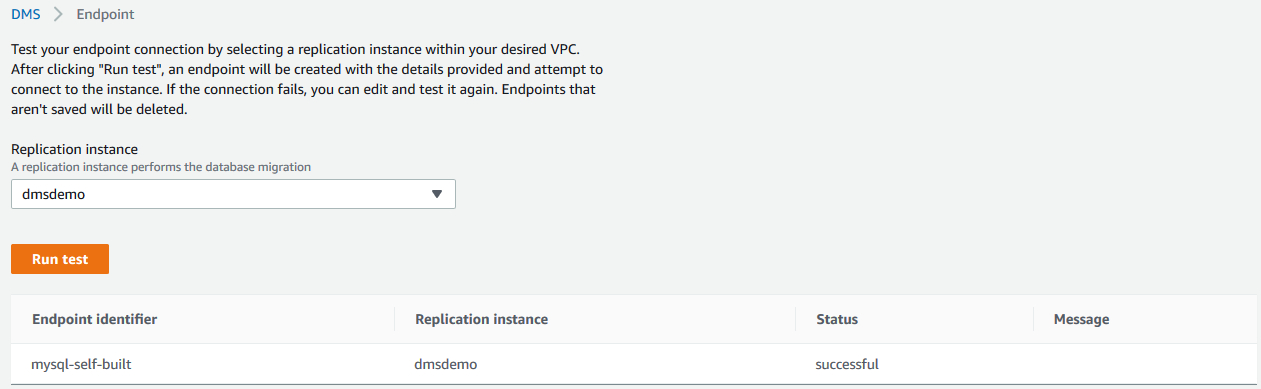
3)创建target endpoint,指向目标数据库。
先创建一个空的、不包含业务数据的Aurora数据库作为目标库,然后创建一个类型为target endpoint、并指向该Aurora数据库的endpoint。
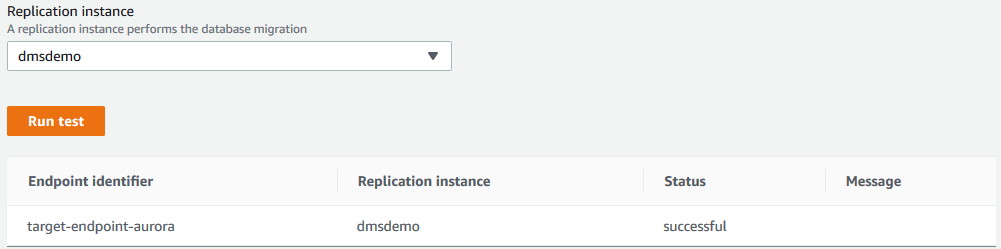
当target endpoint创建完毕以后,我们可以进行连接测试:
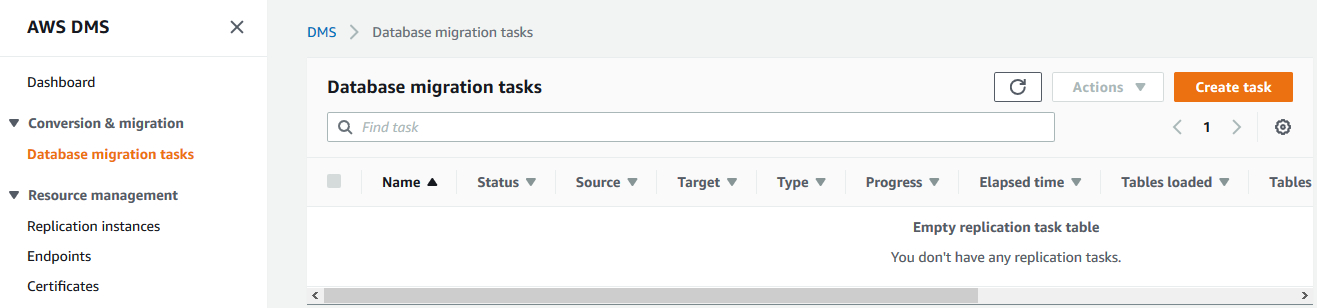
4)创建task,启动复制任务。
创建了源和目标endpoint以后,可以开始创建复制任务。选择Database migration tasks链接,然后选择Create task按钮。
在创建任务的界面上,选择之前创建的source endpoint和target endpoint,migration type选择Migrating existing data and replicate ongoing changes,同时选择Enable CloudWatch logs复选框。在Selection rules部分,我们指定把MySQL里的myaurora数据库的数据复制到Aurora里,如下图所示:
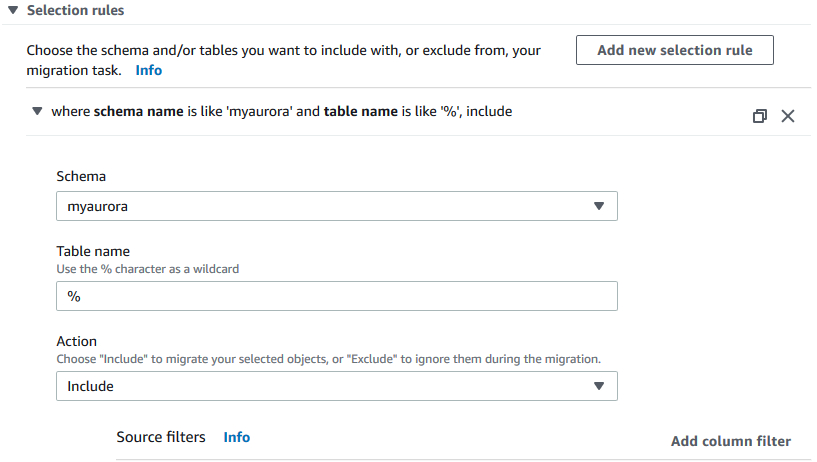
参考https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.Creating.html 文档了解其他选项的含义。在设置好参数以后,点击Create task按钮。
等到任务正常运行以后,则源MySQL数据库和目标Aurora数据库之间就通过DMS服务进行数据同步,并且该同步过程是同步增量数据。如下图所示:
当需要进行数据库切换的时候,通常都是业务低谷的时间段:
- 停止应用程序向MySQL数据库写入数据。
- 等到所有数据都同步到Aurora以后,停止DMS任务。
- 修改应用程序的连接字符串,使其指向Aurora数据库,则可以完成整个迁移过程。
使用AWS DMS把自建的MySQL数据库迁移到Aurora数据库的最大好处,在于整个操作过程非常简单,没有太多的步骤,也就不容易出错。在进行DMS迁移的过程中,参考如下的建议:
- 如果要迁移的数据库很大,则建议使用较大的机型作为复制实例
- 把小的表集中作为一个任务进行复制。而把每个较大的表作为一个单独的任务进行复制。
结论
本文按照从简单到复杂的顺序,详细描述了各种场景下,MySQL数据库如何迁移到Amazon Aurora数据库上。客户可以根据自己的实际场景,选择自己最适合的方式进行数据库的迁移。
针对离线数据如何将 MySQL 数据库迁移到 Amazon Aurora 数据库
有很多用户在本地或云中使用标准 MySQL 来持久化业务数据,现在他们希望能使用新一代基于云架构的 Amazon Aurora 数据库。 使用 Amazon Aurora 数据库有非常多的好处,她的性能比普通的 MySQL 数据库高数倍,并且很容易能横向及纵向扩展。对于已有系统,首先会面对如何将现有数据库迁移到 Amazon Aurora 中。下面将介绍如何将一个 AWS 云中 Amazon Linux 上的 MySQL 迁移到 Amazon Aurora 的全过程,迁移的过程分为下面几个步骤:
- 安装 Percona XtraBackup 备份工具
- 备份 MySQL 数据库
- 将备份 MySQL 文件上传到 S3
- 在 Aurora Console 中还原备份文件到 Amazon Aurora
对于数据中心的 MySQL ,整个迁移过程是类似的。
Percona XtraBackup 备份工具
XtraBackup 是 MySQL 的一个开源热备份的工具,能支持全备及增量备份等。和 mysqldump 相比, mysqldump 是将数据库转换为 SQL 语句,再应用到目标数据库去。因此迁移较大 MySQL 数据库到 Aurora 时, mysqldump 的方式效率太低。而 XtraBackup 备份的是数据库的二进制数据及日志等,并且文件可以压缩,这样文件更小,因此备份和还原都更快。因此对于大数据库推荐用XtraBackup备份的方式进行迁移。
- 下载 Percona yum repository
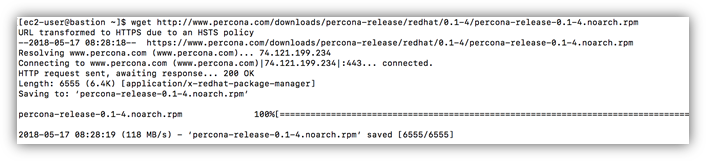
由于 Percona XtraBackup 安装地址并不在 yum 的默认仓库(repository)里,因此运行下面命令下载并安装:
wget: http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
运行结果如下图所示:
- 安装 Percona yum repository
使用下面命令安装已下载的 rpm 包,sudo rpm -ivh percona-release-0.1-4.noarch.rpm
结果如下图所示:

- 检查 yum repository 的安装结果
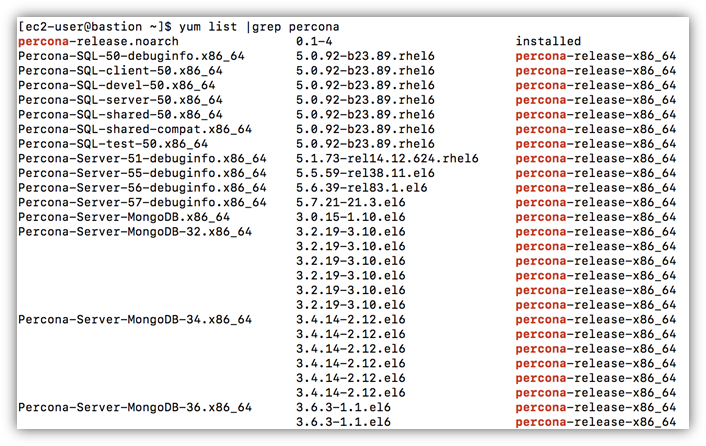
运行 yum list 命令检查 percona 相关的 repository 是否被正确安装。如下命令:yum list |grep percona
命令输出类似下图:
- 安装 percona-xtrabackup 工具
运行下面 yum 命令直接安装 percona-xtrabackup 包,必须安装2.3版本以上软件。yum install percona-xtrabackup-24
输出结果如下图所示:
安装成功后,应该显示安装成功信息如下图所示:
备份 MySQL 数据库
运行下面命令备份 MySQL 实例为压缩文件。
sudo innobackupex -u root -ppassword --stream=tar /tmp | gzip -9 > ./prod_db.tar.gz
整个备份过程如下图所示:
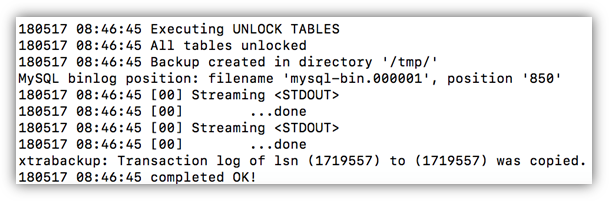
你会看到最后显示备份成功。
xtrabackup: Transaction log of lsn (1719557) to (1719557) was copied. 180517 08:46:45 completed OK!
将备份文件上传到 S3
- 安装本地 CLI 命令行工具
使用下面命令配置命令行访问 aws 资源:aws configure
如果不了解如何配置命令行工具,请参考:
https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-chap-getting-started.html - 将文件上传到 Aurora 数据库相同 Region 的 S3 bucket。

- 在 S3 上检查文件是否上传成功(也可以在命令行中直接检查)
在 Aurora Console上将 MySQL 备份文件还原为 Aurora 数据库
- 在 RDS Console 上点击 ”Restore Aurora DB cluster from s3” 开始还原过程。
- 指定具体备份信息
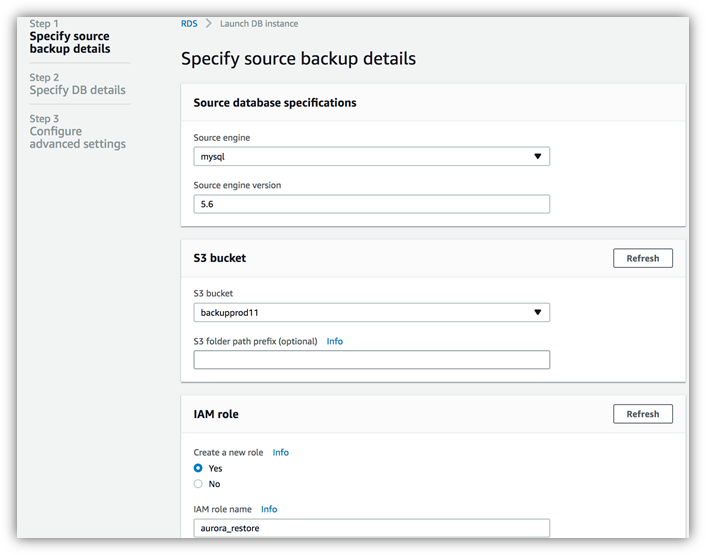 Source engine
Source engine
当前只支持 MySQL 引擎的 S3 迁移。Source engine version
源 MySQL 数据库的版本,当前支持5.5及5.6版本。S3 bucket
上传到 s3 上 bucket 的路径。IAM role
创建一个新的角色,此角色用来授权 Aurora 访问 s3 中的备份文件。IAM role name
指定新创建角色的名称。 - 指定要还原 Aurora cluster 的信息
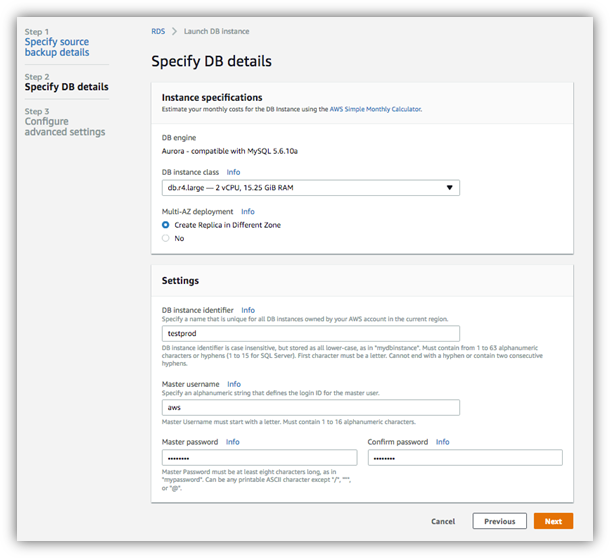 DB Engine
DB Engine
显示当前 Aurora MySQL 的引擎版本。DB Instance class
定义 Aurora 的 master 节点容量大小,临时测试环境可以使用 t 系列的机型,生产环境可以使用r系列的机型。请根据生产的压力选择合适大小的机型。Create Replica in Different Zone
Aurora 是一个集群数据库,这个集群数据库可以有一个主节点和多个 read replica 的只读节点。如果 read replica 节点分布在多个可用区,则当主节点可用区不可用时,数据库可以切换到另外一个可用区的 read replica。Settings
数据库基本信息设置。 - 指定 Aurora 环境信息
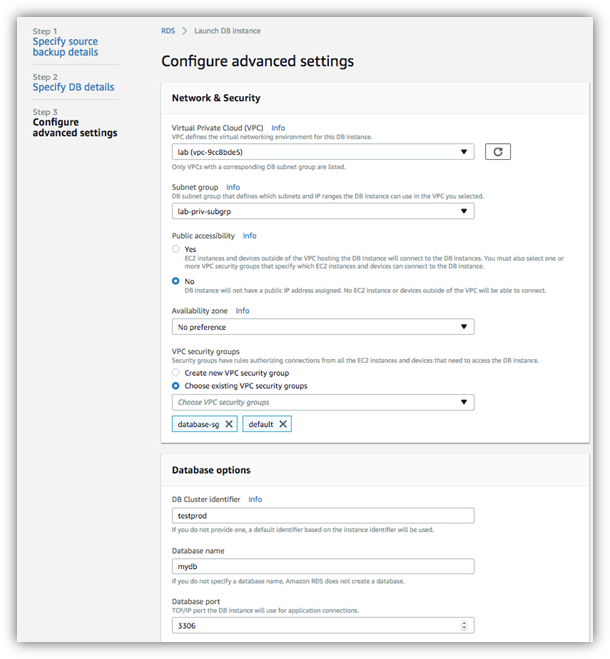 VPC
VPC
指定 Aurora 数据库需要创建在哪个 VPC 下。Subnet group
指定在哪个子网组中创建 Aurora 实例,请在 RDS Console 主页左侧 subnet groups 列表下定义子网组。Public accessibility
指定数据库是否公网可访问,一般生产数据库都设置成内网访问的模式。如果你选择的子网组是都是私有子网,则你设置成公有访问,也无法访问数据库。VPC Security group
设置安全组的信息,请确保你向目标访问 aurora 的机器开放3306端口 - 还原后去 RDS Console 中确认数据库还原成功。
总结
从上面可以知道,我们只需要几个简单的步骤,就可以将 MySQL 数据库备份然后恢复成一个 Aurora 数据库了,小伙伴们还等什么,赶紧去试试吧!
Amazon Aurora MySQL 数据库配置的最佳实践
在 AWS 云中迁移或启动新的 Amazon Aurora MySQL 实例后,您是否问过自己类似以下的问题?
- “接下来要做什么? 如何让它以最佳方式运行?”
- “是否应该修改任何现有参数?”
- “我应该修改哪些参数?”
如果您问过这样的问题,我希望这篇博文可以就应做事项(以及不应做事项)提供一些指导。
在本文中,我将讨论、阐明并提供有关 Amazon Aurora 的 MySQL 兼容性配置参数的建议。此等数据库参数及其值对于在 AWS 云中传递、调整或重新配置新创建或迁移的实例非常重要。我还会讨论哪些参数会从 Amazon RDS for MySQL 实例传递到 Aurora 实例。相关内容将涉及哪些是默认值,以及哪些参数对于实例的稳定性和最佳性能至关重要。
更改参数之前最重要的考量因素是了解更改背后的需求和动机。 虽然大多数参数设置都可以使用默认值,但是应用程序工作负载的变化可能会导致这些参数需要调整。在进行任何更改之前,请先问自己以下问题:
- 我是否遇到稳定性问题,例如重启或故障转移?
- 我能让我的应用程序更快地运行查询吗?
Aurora 参数组快速入门
Aurora MySQL 参数组有两种类型:数据库参数组和数据库集群参数组。一些参数会影响整个数据库集群的配置,如 binlog 格式、时区和默认字符集。另一些参数将其作用范围限制为单个数据库实例。
在这篇博文中,我会从另一种意义上将其做以分类:哪些参数会影响您 Aurora 集群的行为、稳定性和功能,以及哪些参数会在修改时影响性能。
请记住,两种参数都是预设默认值的即用式参数,有些参数允许修改。
如果想要回顾和深入了解修改和使用参数组的基础知识,请参阅 Aurora 用户指南中的以下主题:
在更改生产数据库之前
参数更改可能会产生意外结果,包括性能下降和系统不稳定。在更改任何数据库配置参数之前,请遵循以下最佳做法:
- 通过创建克隆或恢复生产实例的快照在测试环境中进行更改(如文档中所述)。这样,您的设置将最大程度地贴近生产环境。
- 模拟生产工作负载为您的测试实例生成工作负载。
- 检查系统性能的关键性能指标,如 CPU 使用率、数据库连接数、内存使用率、缓存命中率和查询吞吐量,还有延迟。在更改前执行此检查以获得基线数值,更改后再次检查以观察结果。
- 一次只更改一个参数,避免混乱。
- 如果更改对测试系统没有产生可测量的影响,请考虑将参数恢复为默认值。
- 记录哪个参数具有您期望的积极影响以及哪些关键绩效指标显示出改进。
默认参数值及其重要性
某些数据库实例参数包含变量或公式,其中值由常量决定。这包括实例的大小和内存占用、实例的网络端口及其分配的存储空间。此类参数最好保持不变,因为当执行实例放大或缩小操作时它们会自动调整。
例如,Aurora DB 参数 innodb_buffer_pool_size 的默认值为:
DBInstanceClassMemory 是一个变量,表示实例的内存大小 (GiB)。
举例来说:对于具有 30.5 GiB 内存的 db.r4.xlarge 实例,此值为 20,090,716,160 字节或 18.71 GiB。
假设我们决定将此参数设置为固定值,比如设置为 18,000,000,000 字节,之后我们对db.r4.large 执行缩减操作,将内存减半(15.2 GiB)。在进行此改动后,我们很可能在数据库引擎上遇到内存不足的情况,并且实例无法正确启动。
要快速浏览系统变量自动计算的参数,可以在参数组定义中搜索这些参数。为此,请搜索大括号字符“{”。
如果要查询实例使用的实际值,可以通过两种方式在命令行中实现。即分别使用 SHOW GLOBAL VARIABLES 或 SELECT 语句:
参数值设置错误的症状和诊断
当某些参数配置错误时,可能会在 MySQL 错误日志中以内存不足的记录体现出来。在这种情况下,实例进入滚动重启状态并生成类似于以下内容的事件日志,且会指明需要调整的参数值:
参数分类
针对本文讨论的内容,我们可以将 Aurora MySQL 参数分为两大类:
- 控制数据库行为和功能但不影响资源利用率和实例稳定性的参数
- 通过管理实例中资源(如缓存和基于内部内存的缓冲区)的分配方式而可能影响性能的参数
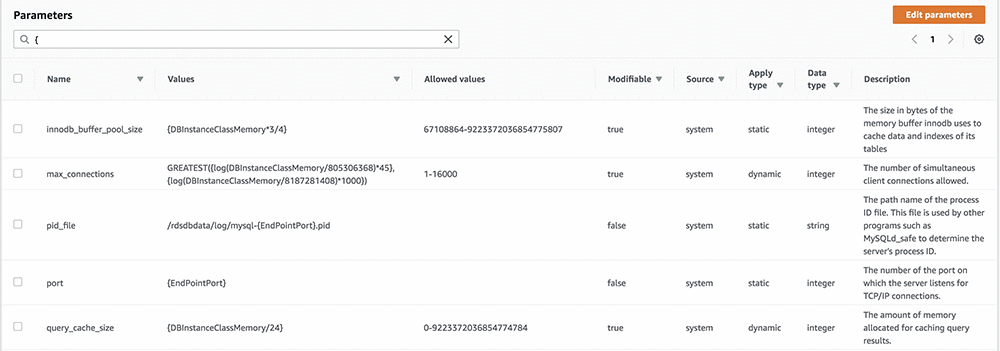
让我们看一下其中的一些参数、它们的默认值以及它们在变动时如何影响实例的行为或性能。下表描述了在参数组中会遇到的参数名称、Aurora 和 MySQL 的默认值以及修改此参数会影响到的功能的摘要。
参数名称 |
影响 |
Aurora 默认值 |
MySQL 5.6/5.7 值 |
参数描述 |
| autocommit | 功能 | 1 (ON) | 1 (ON) | 启用时,会自动向磁盘提交事务。如果禁用,多语句事务必须要显式地启动并提交或回滚。如果未显式启动事务,则会自动提交每个成功语句。 |
| max_connections | 功能 | {Variable} | {Variable} | 限制数据库并发连接的最大数量。 |
| max_allowed_packet | 功能 | 4194304(字节) | 4194304(字节) | 服务器可接收包的最大大小。 |
| group_concat_max_len | 功能 | 1024(字节) | 1024(字节) | 服务器返回的 GROUP_CONCAT() 函数的最大结果长度。 |
| innodb_ft_result_cache_limit | 功能 | 2000000000(字节) | 2000000000(字节) | 限制 InnoDB 全文搜索查询结果的缓存大小。 |
| max_heap_table_size | 功能 | 16777216
(字节) |
16777216
(字节) |
限制用户新定义的 MEMORY 表的大小。不会限制已有表的大小。 |
| performance_schema | 功能 | OFF | OFF | 启用或禁用 MySQL 性能架构。 |
| binlog_cache_size | 性能 | 32768
(字节) |
32768(字节) | 控制二进制日志缓存大小,增加其值可改善处理大事务的系统的性能。在具有大量数据库连接的环境中应限制该值。 |
| bulk_insert_buffer_size | 性能 | – | – | 控制 MyISAM 缓存大小以加速批量插入操作。不用于 Aurora MySQL。 |
| innodb_buffer_pool_size | 性能 | {Variable}
实例内存的 3/4 |
134217728
(128 MB) |
控制缓存表和索引数据的 InnoDB 缓冲池的内存大小。 |
| innodb_sort_buffer_size | 性能 | 1048576
(字节) |
1048576
(字节) |
定义在写入磁盘之前,将多少数据读取到内存进行排序操作。 |
| join_buffer_size | 性能 | 262144
(字节) |
262144
(字节) |
未索引的连接、索引以及范围扫描的最小缓冲区大小。 |
| key_buffer_size | 性能 | 16777216
(字节) |
8388608
(字节) |
MyISAM 表的键缓存。不用于 Aurora。 |
| myisam_sort_buffer_size | 性能 | 8388608
(字节) |
8388608
(字节) |
MyISAM 索引缓冲区。不用于 Aurora。 |
| query_cache_size | 性能 | {Variable} 1/24 内存大小 | 1048576
(字节) |
缓存结果集的预留内存量,为 1,024 的倍数。 |
| query_cache_type | 性能 | 1 | 0 | 启用或禁用查询缓存。 |
| read_buffer_size | 性能 | 262144
(字节) |
262144
(字节) |
控制多种类型缓冲区的内存分配,例如为ORDER BY 子句、分区插入和嵌套查询排序行时。 |
| read_rnd_buffer_size | 性能 | 524288
(字节) |
262144
(字节) |
改善使用多范围读取查询的系统的性能。 |
| table_open_cache | 性能 | 6000 | 2000 | 限制为所有线程在内存中打开的表数量。 |
| table_definition_cache | 性能 | 20000 | {Variable} 小于 2000 | 限制不使用文件描述符存储在缓存中的表定义的数量。 |
| tmp_table_size | 性能 | 16777216
(字节) |
16777216
(字节) |
限制引擎内部内存中临时表的大小。 |
建议和影响
以下是关于每个关键参数如何影响数据库的简要说明,以及有关如何调整它们的一些用例:
autocommit
推荐设置:使用默认值(1 或 ON)确保每个SQL 语句在运行时自动提交,除非它是用户打开的事务的一部分。
影响:值为 OFF 可能会导致不正确的使用模式,例如事务保持打开时间超过要求、事务未关闭或根本未提交。这可能会影响数据库的性能和稳定性。
max_connections
推荐设置:默认(变量值)。使用自定义值时,仅按照应用程序主动用于执行工作的连接数进行配置。
影响:即使没有主动使用连接,配置过高的连接限制也会导致过高的内存使用量。它还可能导致高数据库连接峰值,进而影响数据库的性能和稳定性。
此变量参数使用以下公式根据实例的内存分配和大小自动填充,因此请首先使用默认值:
例如,对于 15.25 GiB 内存的 Aurora MySQL db.r4.large 实例,该值设置为 1,000:
如果在错误日志中遇到连接错误并且有大量 Too many connections 消息,则可以将此参数设置为固定值而不是变量设置。
当您考虑将 max_connections 设置为固定值时,如果您的应用程序需要更多的连接,请考虑在应用程序和数据库之间使用连接池或代理。如果无法可靠地预测或控制连接,也可以执行此操作。
手动配置此参数的值超过建议的连接数时,数据库连接的 Amazon CloudWatch 指标会在超出阈值处显示一条红线。这是 CloudWatch 使用的公式:
例如,对于内存大小为 15.25 GiB(15.25 x 1024 x 1024 x 1024 = 16374562816 字节)的 db.r4.large 实例,警告阈值大约为 1,300 个连接。您仍然可以使用最大数量的配置连接,只要实例上有足够的资源。
max_allowed_packet
推荐设置:默认值(4,194,304 字节)。仅在数据库工作负载需要时使用自定义值。在处理返回大型元素(如长字符串或 BLOB)的查询时,请调整此参数。
影响:在此处设置较大的值不会影响消息缓冲区的初始大小。相反,如果查询需要,它允许缓冲区增大到定义的大小。大参数值配上符合条件的大量并发查询,会增加内存不足的风险。
将此参数设置得太小时,会显示以下示例错误:
group_concat_max_len
推荐设置:默认值(1,024 字节)。仅在工作负载需要时才使用自定义值。仅当您想要更改 GROUP_CONCAT() 语句的返回值并允许引擎返回更长的列值时,才需要调整此参数。此值应与 max_allowed_packet 一同使用,因为这将确定响应的最大大小。
影响:将此参数设置得过高的一些症状是高内存使用量和内存不足。将其设置得太低会导致查询失败。
innodb_ft_result_cache_limit
推荐设置:默认值(2,000,000,000 字节)。根据您的工作负载使用自定义值。
影响:由于该值已接近 1.9 GiB,将从其默认值调高可能会导致内存不足。
max_heap_table_size
推荐设置:默认值(16,777,216 字节)。限制用户定义的在内存中创建的表的最大大小。 更改此值仅对新创建的表有影响,不会影响现有表。
影响:如果内存中表增多,则将此参数设置得太高会导致内存使用量过大或内存不足。
performance_schema
推荐设置:由于内存使用率高,t2 实例禁用。
影响:在 Aurora MySQL 5.6 中,性能架构内存是启发式预分配的。此预分配基于其他配置参数,如 max_connections、table_open_cache 和 table_definition_cache。在 Aurora MySQL 5.7 中,性能架构内存按需分配。性能架构通常使用约 1 到 3 GB 的内存,具体取决于实例类、工作负载和数据库配置。如果数据库实例内存不足,启用性能架构可能会导致内存耗尽。
binlog_cache_size
推荐设置:默认值(32,768 字节)此参数控制二进制日志缓存可以使用的内存量。增加该值可以使用缓冲区来避免过量的磁盘写入,提高具有大事务的系统的性能。此缓存按连接分配。
影响:在具有大量数据库连接的环境中限制此值,以避免内存不足的情况。
bulk_insert_buffer_size
推荐设置:保持原样,因为它不适用于 Aurora MySQL。
innodb_buffer_pool_size
推荐设置:默认(变量值),因为它在 Aurora 中预配置为实例内存大小的 75%。您可以在 SHOW ENGINE INNODB STATUS 的输出中看到缓冲池使用量。
影响:较大的缓冲池通过在重复访问相同的表数据时允许较少的磁盘 I/O 来提高整体性能。加上 InnoDB 引擎的开销,实际分配的内存量可能略高于实际配置的值。
innodb_sort_buffer_size
推荐设置:默认值(1,048,576 字节)
影响:高于默认值会增加具有大量并发查询的系统的总体内存压力
join_buffer_size
推荐设置:默认值(262,144 字节)。此值预先分配用于各种类型的操作(例如连接),单个查询可以分配此缓冲区的多个实例。如果要改善连接的性能,我们建议您为这些表添加索引。
影响:更改此参数可能会在具有大量并发查询的环境中导致严重的内存压力。即使添加索引,增加此值也不会提供更快的 JOIN 查询性能。
key_buffer_size
建议设置:保留默认值(16,777,216 字节),因为它与 Aurora 无关并且仅影响 MyISAM 表性能。
影响:对 Aurora 的性能没有影响。
myisam_sort_buffer_size
推荐设置:保留默认值(8,388,608 字节)。它不适用于 Aurora,因为它对 InnoDB 没有影响。
影响:对 Aurora 的性能没有影响。
query_cache_size
推荐设置:默认(变量值)。该参数在 Aurora 中进行了预调整,并且该值远大于 MySQL 默认值。Aurora 的查询缓存不会受到扩展性问题的拖累(如 MySQL 中的查询缓存一样)。可以修改它以满足高吞吐量、高要求的工作负载。
影响:通过此缓存访问查询时,查询性能会受到影响。您可以在“QCache”部分下的 SHOW STATUS 命令的输出中看到查询缓存的使用情况。
query_cache_type
推荐设置:启用。默认情况下,在 Aurora 中启用查询缓存,建议将其保持启用以提高性能,降低开销。但是,如果您知道工作负载不会从中受益,则可以禁用查询缓存。一个例子是工作负载中写入操作繁重,但很少或没有读取查询的情况。
影响:如果工作负载复用查询(如可重复的 SQL 语句),则在 Aurora 中禁用查询缓存可能会影响数据库性能。您可以在“Qcache”部分下的 SHOW STATUS 命令的输出中看到查询缓存的使用情况。
read_buffer_size
推荐设置:默认值(262,144 字节)。
影响:较大的值会导致较高的总体内存压力并引发内存不足问题。除非您能够证明较高的值可以在不影响稳定性的情况下提高性能,否则请不要提高此设置。
read_rnd_buffer_size
推荐设置:默认值(524,288 字节)。由于底层存储集群的性能特征,Aurora 无需增加该设置。
影响:较大的值可能会导致内存不足问题。
table_open_cache
建议设置:保持不变,除非您的工作负载需要同时访问大量表。表缓存是主要的内存使用者,Aurora 中的默认值明显高于 MySQL 默认值。此参数基于实例大小自动调整。
影响:具有大量表(数十万级别)的数据库需要更大的设置,因为并非所有表都适合内存。此值设置太高可能会导致内存不足。如果启用了性能架构,此设置也会间接提高性能架构内存使用量。
table_definition_cache
推荐设置:默认值。此设置在 Aurora 中被预先调整为远大于 MySQL,并且它会根据实例大小和类自动调整。如果您的工作负载需要它,并且您的数据库需要同时打开大量表,增加此值可能会加快打开表操作。此参数与 table_open_cache 一起使用。
影响:如果启用了性能架构,此设置也会间接增加性能架构内存使用量。请注意高于默认值的设置,因为它们可能会引发内存不足问题。
tmp_table_size
推荐设置:默认值(16,777,216 字节)。此参数与 max_heap_table_size 一起用于限制查询处理所使用的内存表的大小。当超出临时表大小限制时,表将交换到磁盘。
影响:非常大的值(数百 MB 或更大)众所周知或会引起内存问题和内存不足错误。此参数不会影响使用 MEMORY 引擎创建的表。
结论和关键要点
在部署新的 Aurora MySQL 实例时,许多参数已经过优化,在执行任何参数更改之前,它们都是一个很好的基准。各参数值的确切组合在很大程度上取决于各个系统、应用程序工作负载和所需的吞吐量特性。此外,在具有高变化率、增长率、数据提取率和动态工作负载的数据库系统上,这些参数还需要持续监控和评估。随着您基于应用程序和业务需求不断调整数据库,我们建议您每隔几个月(可能每隔几周)进行一次监控和评估。
为了执行成功的参数调整,将之转化为可量度的性能提升,您最好进行实验,建立基线并比较执行更改后的结果。我们建议您在将更改提交到实时生产系统之前执行此操作。
如果您想了解有关特定参数的更多信息,请联系 AWS Support 或您指定的 AWS 技术账户团队。