网上中文资料几乎没有关于EC2平台的Hadoop的集群搭建,英文资料碍于英语水平,同时加上关键点说明的也比较分散,整理下整个配置过程,也当重新巩固下为需要的朋友搭建少走弯路。
一、新建Instance
在EC2控制台上新建三个instance,具体的可以参照EC2instance的建立。可以分别取名master,slave1和slave2,其中master将作为namenode和jobtracker,slave1和slave2将作为datanode和tasktracker。(这里使用的是free tire elible的ubuntu 12.10服务器)。
选中一个服务器,在页面下半部会出现instantce的外部dns地址,用来远程访问,比如我这里master的地址为:ec2-54-251-208-185.ap-southeast-1.compute.amazonaws.com。
二、SSH的配置
aws instance之间通信使用RSA加密,在建立instance时会自动下载一个.pem文件,这个就是RSA的私钥,而公钥在建立instance的时候就已经自动设置好了。
运行cmd,输入ssh 命令连接master,需要用-i参数指明本地私钥的位置,替换红色部分
ssh -i your/path/to/your.pem ubuntu@your.instance.adress , ubuntu是aws中所有ubuntu instance的默认用户名。例如:
登陆成功后进入~/.ssh目录,
cd ~/.ssh
新建一个id_rsa文件,
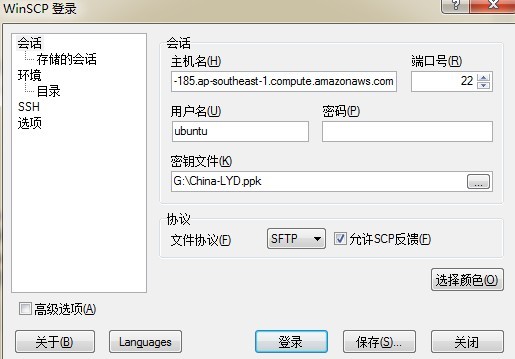
这里用的是winscp(没有的可以上网搜索下载)。如下图:
登录后,找到/home/ubuntu/.ssh,进入后,在里面新建 id_rsa。然后用记事本之类的工具打开本地的私钥文件,全部复制到id_rsa中,保存关闭。
将文件权限降低至600。
chmod 600 id_rsa
然后设置ssh代理,
ssh-agent bash
ssh-add
若出现Identity added: /home/ubuntu/.ssh/id_rsa (/home/ubuntu/.ssh/id_rsa)则表示设置成功,此时可以试着在master上ssh其他slave看是否成功。
以上是关键的步骤之一,因为hadoop工作时需要master和slave之间的交互,而在EC2平台上任意instance之间交互都是需要进行RSA验证的。至此,master与slave之间通信可自动完成验证过程。
三、下载hadoop和java运行环境
这里使用hadoop1.0.4和jdk7
sudo apt-get update
sudo apt-get install openjdk-7-jdk
wget http://www.fayea.com/apache-mirror/hadoop/common/hadoop-1.0.4/hadoop-1.0.4.tar.gz
(需要说明的是,上面的下载地址不能保证你也能够下载,所以去hadoop官方网站找:
hadoop下载地址)。
解压hadoop
tar xzf hadoop-1.0.4.tar.gz
这一步之后很多教程建议将解压之后的文件夹放到/usr/local/目录下,可是如若如此会遇到很多关于用户权限的麻烦,因此这里就将其放在原位(/home/ubuntu/)。
对所有的slave进行相同操作。
四、配置相关参数。
先将hadoop-1.0.4重命名下:
sudo mv hadoop-1.0.4 hadoop
回到master,进入hadoop/conf 目录,
cd ~/hadoop/conf
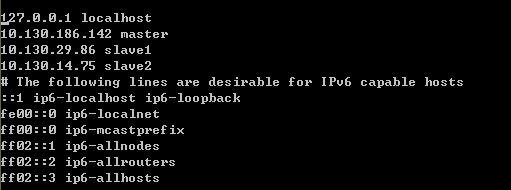
1.设置好三台机器上的/etc/hosts和/etc/hostname
host这个文件用于定义主机名与IP地址之间的对应关系。图所示为我的配置:
原本在第一行和第五行之间是没有内容的,这些内容是加上去的。那么这里要说下如何弄得ip地址了,在/etc/hostname里面。在AWS建立的虚拟机,用的主机名即是ip地址。
用vim /etc/hostname
你将可以看到里面内容为:ip-10-130-186-142。这个就是这台虚拟机的ip地址了,记下后,将这个名字改为master或者slave1或者slave2,这样方便。
使用vim,如果出现无法保存,如图:
那么输入:w !sudo tee %
之后强制退出即可。
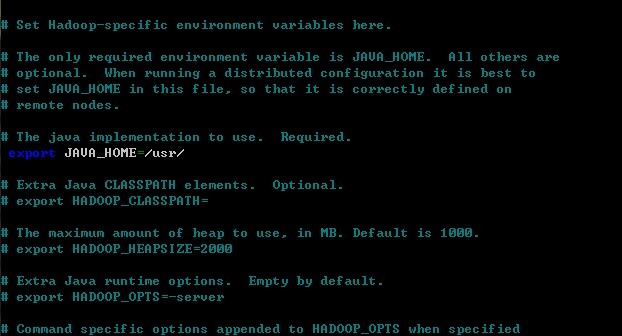
2.修改hadoop-env.sh中的JAVA_HOME参数
vim hadoop-env.sh(当然也可以nano hadoop-env.sh,甚至也可以用之前提到的winscp工具)
具体vim,nano如何使用,自己网上找操作方法
将JAVA_HOME那一行去掉注释,后面修改为
JAVA_HOME = /usr/
如图:
此路径(仅)适用于EC2 ubuntu instance
3.修改core-site.xml
该配置文件指明了HDFS文件系统的服务器以及服务器内路径位置,加入如下配置:
nano core-env.xml
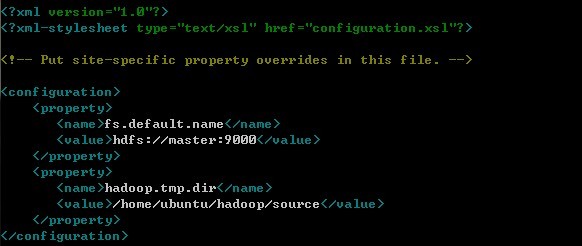
这里的master就是在之前/etc/hosts里面定义的主机名与IP地址之间的对应关系。而第二个value中间的路径是hadoop存储数据的位置,这个可以根据个人有所不同,但此文件夹需要手动创建。
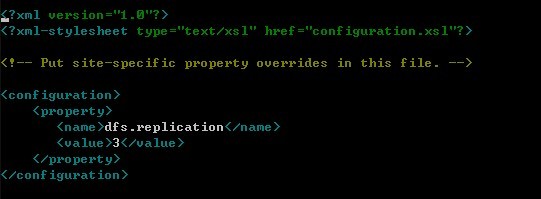
4.修改hdfs-site.xml
该配置文件指明了文件需要备份的份数。加入如下配置:
nano hdfs-site.xml
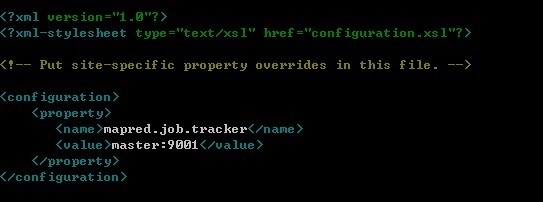
5.修改mapred-site.xml
该配置文件指明了jobtracker的地址,以及其他和MapReduce相关的配置。此处只设置jobtracker为master
加入如下配置:
nano mapred-site.xml
6.masters和slaves两个文件中需要分别申明一下master和slave1,slave2外部dns地址
可以看到里面只是写了master slave1 slave2。这些在之前/etc/hosts里面已经定义的主机名与IP地址之间的对应关系。

7.用scp命令将master的配置推送到slave
先回到master。确认自己是在/home/ubuntu/hadoop/conf目录下。输入如下命令(红色部分填写slave1,slave2的ip地址):
scp * your.slave1.ipadress:/home/ubuntu/hadoop/conf/
scp * your.slave2.ipadress:/home/ubuntu/hadoop/conf/
如果这一步失败,提示”public key denied”说明ssh代理设置不成功。
至此,instance配置全部完成。
五、配置EC2 Security Group
Security Group 起到了instance的分组和防火墙的作用。如下图所示,目前Security Group只开放了22(SSH)端口,Source 0.0.0.0/0 表示允许任意来源访问该端口。
还记得之前配置HDFS和JobTracker的时候用到了9000和9001端口吗?这些端口默认没有打开,但却是Hadoop运行所必须的。
在左侧添加Hadoop所需的端口,并将source设置成instance所在的Security group,点击Apply Rule Changes ,完成后如下图所示。

至此,就结束配置了。
六、运行Hadoop
1.进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作。
cd /home/ubuntu/hadoop
bin/hadoop namenode -format
2.启动bin/start-all.sh
bin/start-all.sh
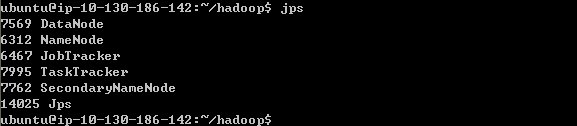
3.检测hadoop是否启动成功
jps
如果有Namenode,SecondaryNameNode,TaskTracker,DataNode,JobTracker五个进程,就说明你的hadoop单机版环境配置好了!如下图:
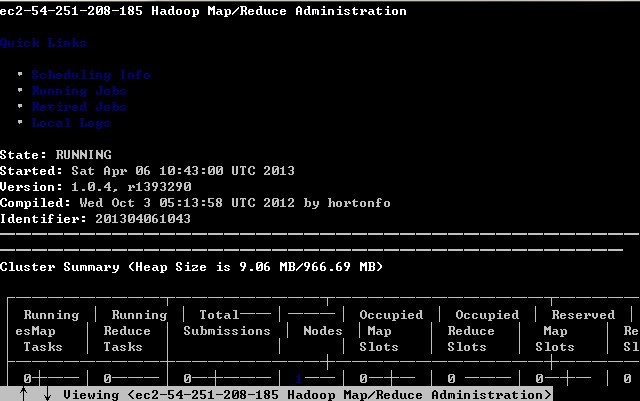
也可以用w3m查看下。
输入:w3m http://master:50030或者w3m http://master:50070查看集群状态。如图:
七、小结
集群配置只须记住conf/hadoop-env.sh、conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml、conf/mapred-queues.xml这5个文件的作用即可。
作为分布式系统,hadoop需要通过SSH的方式启动处于slave上的程序,因此必需安装和配置SHH。所以说安装hadoop前需要安装JDK和SSH。
下面两种方法在实际应用中也可能会用到:
1.重启坏掉的DataNode或JobTracker。
当hadoop集群的某单个节点出现问题时,一般不必重启整个系统,只须重启这个节点,它会自动连入整个集群。
在坏死的节点上输入如下命令即可:
bin/hadoop-daemon.sh start DataNode
bin/hadoop-daemon.sh start jobtracker
2.动态加入DataNode或TaskTracker。这个命令允许用户动态将某个节点加入集群中。
bin/hadoop-daemon.sh –config ./conf start DataNoda
bin/hadoop-daemon.sh –config ./conf start tasktracker
 QQ咨询
QQ咨询