 QQ咨询
QQ咨询
Amazon EC2 Container Service上实现服务高可用的自动伸缩
1. 简介
Amazon EC2 Container Service (ECS)是Amazon提供的一项Docker容器管理服务,可以让您轻松构建、运行、管理您的Docker容器服务。ECS Service是ECS的重要组件,它可以在集群中运行指定数量的任务,当某个任务不可用时,它会重新启动新的任务,维持住任务的指定数量。这个特性从一定程度上保证了服务的可用性,但当面对突发流量,ECS本身并不能动态地进行任务数量的扩展,当流量较少时,ECS也无法动态地进行任务数量的缩减。为解决此问题,可以使用Auto Scaling和Amazon CloudWatch等实现服务的自动伸缩,保证服务高可用。本文将介绍一个运用Auto Scaling在ECS中实现服务高可用的方案,并通过对方案构建过程的剖析,让您对高可用、自动伸缩的服务架构有更进一步的了解。
2. 方案构建
2.1 整体结构图
本方案使用AWS CloudFormation模板声明整个资源堆栈所需资源和相关配置,并实现自动化构建。关于AWS CloudFormation相关知识,请通过以下链接了解:CloudFormation入门。
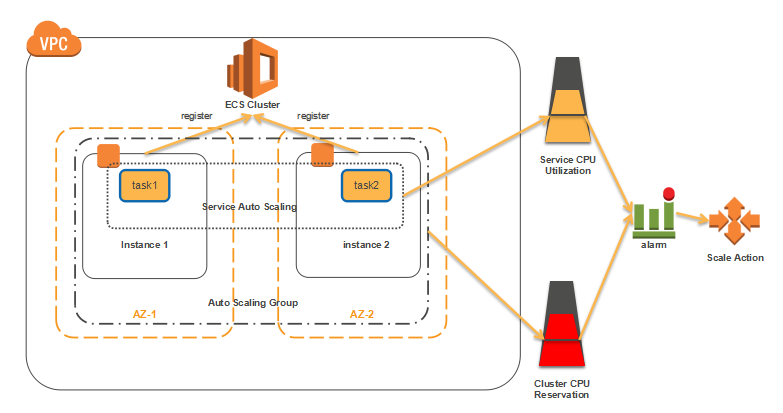 从上面这个结构图可以看出以下主要组成部分:
从上面这个结构图可以看出以下主要组成部分:
- 初始由两个跨AZ的Container Instance组成的ESC Cluster。
- 初始ESC Service中有两个task。
- Service Auto Scaling与CloudWatch结合,当Service维度的 CPUUtilization与Threshold满足设定的触发条件时,触发CloudWatch Alarm,CloudWatch Alarm根据设定的Scaling Policy进行Task数量伸缩。
- Auto Scaling Group与CloudWatch结合,当Cluster维度的CPUReservation与Threshold满足设定的触发条件时,触发CloudWatch Alarm,CloudWatch Alarm根据设定的Scaling Policy进行实例数量的伸缩。
2.2 准备工作
(1)准备好CloudFormation模板脚本
请从这里(点我)下载用于构建整个资源堆栈的模板脚本文件。
或者通过点击下面按钮来运行堆栈:
![]()
(2)准备好Lambda Function
本方案在Auto Scaling Group中的实例关闭时,会调用一个实现自动切换Draining状态的Lambda Function。那么在构建整个堆栈之前,需要先准备好这个Lambda Function。这里我们使用Python编写了这个脚本auto_drain.py来实现此功能。您可以了载包含了这个脚本的压缩包(点我)。
下载完成后,请将它上传到您账户上同个Region的S3 Bucket中。记住这个S3 Bucket Name,在构建堆栈时,将它传给Lambda Function S3 Bucket 这个参数。
2.3 构建过程
(1)构建堆栈
打开您的CloudFormation控制面板,使用模板脚本创建堆栈,创建成功后,打开堆栈“输出”栏,可以看到ALBDNS输出值如下所示:

将这个URL复制到浏览器访问,看到It Works字样,表示堆栈构建成功。
(2)测试service auto scaling
我们在模板中定义了基于ECS Service维度的CPU使用率(CPU Utilization)指标进行自动伸缩service的task个数。初始状态下,我们设置Service的Desired Count(参见模板中的ServiceDesiredCount参数)为2,查看ECS Service Management Console,选中左边栏“集群”,再选中as-demo-cluster,点击“ECS Service实例”。可以看到现在有两个容器实例,每个容器实例运行一个任务,总共有两个任务。

接下来我们利用Apache ab压测工具进行测试,向我们的ALB发送30000条请求,并发为每秒1000。相应的ab命令如下:
| $ ab -n 300000 -c 1000 http://as-in-publi-xxxxxxxxxxxxxx/ |
等待ab请求运行完成后,查看此时ECS Service中实例的状态,如下图所示,可以发现在某台实例上新增加了一个task,总的task数量变成了3个,也就是成功触发了Service Scale out。

等待几分钟,再次查看ECS Service中实例的状态,可以看到task总数量又变成了2个,即当Service CPUUtilization小于我们设的的Threshold一定时间(默认设置的是5分钟)后,自动触发了Service Scale in。

(3)测试cluster auto scaling
同样使用Apache ab进行压测,不过为了达到效果,需要加大请求数量和并发数量。
使用以下ab命令(当然您可以根据自己实际情况进行调整)
| $ ab -n 1000000 -c 2000 http://as-in-publi-xxxxxxxxxxxxxx/ |
如果遇到 socket:Too many open files异常。可以使用以下命令修改linux系统最大打开文件数
| $ ulimit -n 2048 |
等待压测结束后,查看ECS中实例的状态(因为实例的启动与容器的启动不同,耗费时间比较长,可能需要等待几分钟才能看到效果),如下图所示,Cluster自动增加了一台实例。

等待一段时间后,再次查看ECS Service中实例的状态,如下图所示,Cluster自动减少了一台实例。

(4)测试自动切换实例Draining状态
我们使用Lambda Function实现在Scale in时自动切换实例到Draining状态(具体讲解见后面章节)。
当前集群中总的实例数量为2,我们通过修改Auto Scaling Group的desired count(在EC2管理窗中界面选中我们模板创建的Auto Scaling Group,修改desired count),将它设为1,这样Auto Scaling会自动关闭一台实例,看看运行的任务数量有什么变化。
可以看到被停掉的实例状态自动切换成了DRAINING,任务也被移到了另一台实例上。
3. 基于两个维度的自动伸缩
CloudWatch监听ECS中的四个指标,分别是CPUUtilization、MemoryUtilization、CPUReservation和MemoryReservation。这四个指标可以分为两大类,前两者是指资源使用率,后两者是指资源占有率。本方案通过集群和服务这两个维度,分别对占用率和使用率进行监控,定制不同的伸缩策略,从而实现自动伸缩。
3.1 什么是资源使用率和资源占有率
资源使用率(CPUUtilization和MemoryUtilization)是指ECS集群(或服务)中所有运行着的任务实际使用资源的总和除以EC2 Container Service集群(或服务)总的资源得到的数值,表现的是集群或服务中资源的使用情况。
资源占有率(CPUReservation和MemoryReservation)是指ECS集群(或服务)中所有运行着的任务申请占有的资源的总和除以EC2 Container Service 集群(或服务)总的资源得到的数值,表现的是集群或服务中资源的剩余情况。
3.2 基于服务中CPU使用率实现服务自动伸缩
为了简单起见,本方案只监控CPU的使用率和占有率。
当服务面对越来越大的流量时,服务中CPU使用率快速上升,这时可以根据这个CPU使用率来动态地增加任务数量,以达到分担负载的作用。而不是根据CPU占有率来进行扩展,因为无论流量如何变大,CPU占用率是与服务中任务数量相关的,任务数量不同,CPU占用率也不会改变。
在本方案中,具体的构建过如下:
(1)首先,我们声明了对服务中task desired count作为Auto Scaling调整的对象ScalableTarget,ResourceId指向我们创建的ECS Service代码如下:
| ServiceScalingTarget:
Type: AWS::ApplicationAutoScaling::ScalableTarget DependsOn: DemoService Properties: MaxCapacity: !Ref ServiceMaxSize MinCapacity: !Ref ServiceMinSize ResourceId: !Join [”, [service/, !Ref ‘ECSCluster’, /, !GetAtt [DemoService, Name]]] RoleARN: !GetAtt [ServiceAutoscalingRole, Arn] ScalableDimension: ecs:service:DesiredCount ServiceNamespace: ecs |
(2)我们声明了两个Scaling Policy,分别针对Scale Out和Scale In两种情况,当Scale Out时修改ServiceScalingTarget中的Service Desired Count,增加1个task;当Scale In时修改ServiceScalingTarget中的Service Desired Count,减少1个task。主要代码如下:
| ServiceScaleOutPolicy:
Type: AWS::ApplicationAutoScaling::ScalingPolicy Properties: PolicyType: StepScaling PolicyName: StepOutPolicy ScalingTargetId: !Ref ‘ServiceScalingTarget’ StepScalingPolicyConfiguration: AdjustmentType: ChangeInCapacity MetricAggregationType: Average StepAdjustments: – MetricIntervalLowerBound: “0” ScalingAdjustment: “1”
ServiceScaleInPolicy: Type: AWS::ApplicationAutoScaling::ScalingPolicy Properties: PolicyType: StepScaling PolicyName: StepInPolicy ScalingTargetId: !Ref ‘ServiceScalingTarget’ StepScalingPolicyConfiguration: AdjustmentType: ChangeInCapacity MetricAggregationType: Average |
(3)最后,我们声明两个CloudWatch Alarm,分别在Service的CPUUtilization满足Threshold关系时,触发Scale Out和Scale In的Alarm。
| ServiceCPUUtilizationScaleOutAlarm:
Type: AWS::CloudWatch::Alarm Properties: EvaluationPeriods: !Ref ServiceCPUUtilizationScaleOutMinutes Statistic: Average Threshold: !Ref ServiceCPUUtilizationScaleOutThreshold AlarmDescription: Alarm if Service CPUUtilization greater then threshold. Period: ’60’ AlarmActions: [!Ref ‘ServiceScaleOutPolicy’] Namespace: AWS/ECS Dimensions: – Name: ClusterName Value: !Ref ECSCluster – Name: ServiceName Value: !GetAtt [DemoService, Name] ComparisonOperator: GreaterThanThreshold MetricName: CPUUtilization
ServiceCPUUtilizationScaleInAlarm: Type: AWS::CloudWatch::Alarm Properties: EvaluationPeriods: !Ref ServiceCPUUtilizationScaleInMinutes Statistic: Average Threshold: !Ref ServiceCPUUtilizationScaleInThreshold AlarmDescription: Alarm if Service CPUUtilization less then threshold. Period: ’60’ AlarmActions: [!Ref ‘ServiceScaleInPolicy’] Namespace: AWS/ECS Dimensions: – Name: ClusterName Value: !Ref ECSCluster – Name: ServiceName Value: !GetAtt [DemoService, Name] ComparisonOperator: LessThanThreshold MetricName: CPUUtilization |
3.3 基于集群中CPU占有率实现集群自动伸缩
当服务中任务的数量随着流量增大也不断增加时,集群中CPU的占有率也会上升,当CPU占有率不断上升,表示可用的资源已不多了,此时需要扩展新的实例,增加整个集群总的资源。
在本方案中,具体的构建过如下:
(1)首先声明两个Scaling Policy,当集群Scale Out时修改集群中的实例数量,增加1个实例;当Scale In时修改集群中的实例数量,减少1个task。主要代码如下:
| ClusterScaleOutPolicy:
Type: “AWS::AutoScaling::ScalingPolicy” Properties: AdjustmentType: “ChangeInCapacity” AutoScalingGroupName: Ref: “ECSAutoScalingGroup” PolicyType: “StepScaling” MetricAggregationType: “Average” StepAdjustments: – MetricIntervalLowerBound: “0” ScalingAdjustment: “1”
ClusterScaleInPolicy: Type: “AWS::AutoScaling::ScalingPolicy” Properties: AdjustmentType: “ChangeInCapacity” AutoScalingGroupName: Ref: “ECSAutoScalingGroup” PolicyType: “StepScaling” MetricAggregationType: “Average” StepAdjustments: – MetricIntervalUpperBound: “0” ScalingAdjustment: “-1” |
(2)我们声明两个CloudWatch Alarm,分别监听的指标是集群的CPUReservation,当CPUReservation满足Threshold设定的关系时,触发Scale Out和Scale In的Alarm。主要代码如下:
| ClusterCPUReservationScaleOutAlarm:
Type: AWS::CloudWatch::Alarm Properties: EvaluationPeriods: !Ref ClusterCPUReservationScaleOutMinutes Statistic: Average Threshold: !Ref ClusterCPUReservationScaleOutThreshold AlarmDescription: Alarm if Service CPUUtilization greater then threshold. Period: ’60’ AlarmActions: [!Ref ‘ClusterScaleOutPolicy’] Namespace: AWS/ECS Dimensions: – Name: ClusterName Value: !Ref ECSCluster ComparisonOperator: GreaterThanThreshold MetricName: CPUReservation
ClusterCPUReservationScaleInAlarm: Type: AWS::CloudWatch::Alarm Properties: EvaluationPeriods: !Ref ClusterCPUReservationScaleInMinutes Statistic: Average Threshold: !Ref ClusterCPUReservationScaleInThreshold AlarmDescription: Alarm if Service CPUUtilization less then threshold. Period: ’60’ AlarmActions: [!Ref ‘ClusterScaleInPolicy’] Namespace: AWS/ECS Dimensions: – Name: ClusterName Value: !Ref ECSCluster ComparisonOperator: LessThanThreshold MetricName: CPUReservation |
4. Cluster scale in时切换实例到Draining保证服务容量
我们的ECS集群并不是一创建好就一成不变的,特别是当集群空闲的时候,触发了EC2的Auto Scaling Group的缩减实例之后. 有些时候我们需要关闭其中某个实例,无论是由于系统升级、安装软件、还是为了节省运行成本。那么在关闭实例时,实例上正在运行的task怎么办呢?把它们全杀掉?那可不行,那样就等于减小了整个ECS服务的容量和负载能力,对性能有很大影响。另外就是当直接关闭EC2机器的时候杀死其中的task, 可能造成运行在上面的task处理的请求异常终止,而影响到我们所提供服务的SLA, 这种情况下,将实例切换到Draining状态就是一种解决方案。
当您要关闭集群中某个实例时,运行在这个实例上的task会被停止,然后ECS会在集群中另一个(或多个)实例上运行这些被停掉的task,从而保证整个ECS Service 的task数量保持不变,保证了整个服务容量和负载能力不受影响。同时,当实例被设置成为Draining状态之后,ECS将会自动平滑关闭EC2宿主机中的task资源,利用定义task模版时候所定义的放置规则,将其移动到其他拥有剩余资源的集群中的宿主机上. 关于实例Draining的更多信息,请参见文档.
在本方案中,我们使用AWS SNS 和Lambda实现了实例在集群的Auto Scaling Group Scale in时关联Auto Scaling的LifecycleHook,实现被关闭前调用Lambda Function自动切换Draining状态,将task转移到集群中其它实例上。
我们定义了一个Lambda Function运行Python脚本auto_drain.py,这个脚本主要完成两个工作:
(1)判断传到Lambda Function中的event是否包含autoscaling:EC2_INSTANCE_TERMINATING,是的话就将这个实例状态切换成Draining,这样ECS就会自动停止此实例上所有运行中的task,并在集群中别的实例启动同样数量的task。
切换实例到Draining状态的代码:
| containerStatus = containerInstances[‘status’]
if containerStatus == ‘DRAINING’: tmpMsgAppend = {“containerInstanceId”: containerInstanceId} else: # Make ECS API call to set the container status to DRAINING ecsResponse = ecsClient.update_container_instances_state(cluster=clusterName, containerInstances=[containerInstanceId],status=’DRAINING’) |
(2)判断实例上还有没有task正在运行中。如果仍然有运行中的task,则过发送一条SNS通知重新触如这个Lambda Function。如果实例上所有task都已经被停止,则解开LifecyleHook,使这个实例被停掉。
根据task运行情况做不同处理的代码:
| # If tasks are still running…
if tasksRunning == 1: response = snsClient.list_subscriptions() for key in response[‘Subscriptions’]: if TopicArn == key[‘TopicArn’] and key[‘Protocol’] == ‘lambda’: snsClient.publish( TopicArn= key[‘TopicArn’], Message=json.dumps(message), Subject=’Publishing SNS message to invoke lambda again..’ ) # If tasks are NOT running… elif tasksRunning == 0: completeHook = 1 try: response = asgClient.complete_lifecycle_action( LifecycleHookName=lifecycleHookName, AutoScalingGroupName=asgGroupName, LifecycleActionResult=’CONTINUE’, InstanceId=Ec2InstanceId) logger.info(“Response received from complete_lifecycle_action %s”,response) logger.info(“Completedlifecycle hook action”) except Exception, e: |
整个Python脚本代码,可以解压您在准备工作中下载的auto_drain.zip,查看auto_drain.py脚本文件。
5. 总结
本文主要介绍了如何在ECS 中使用 Auto Scaling、Amazon CloudWatch和其他常用AWS服务实现高可用,可伸缩的服务架构,并结合Lambda Function和AWS SNS 做到当集群中由于Auto Scaling缩减关闭某个实例时,自动切换实例状态到Draining,将task转移到其他实例上,保证服务容量以及回收实例资源时候的task的平滑过渡。通过本套方案,可以让ECS服务在可用性和伸缩性上得到保证,从而为您解决实际业务场景中相类的问题提供一定的帮助和思路。您也可以在本方案基础上,结合实际业务需求,定制自己的Scaling Policy、监控指标和监控维度,实现更符合您需求的解决方案。