 QQ咨询
QQ咨询
使用CloudWatch Logs,Kinesis Firehose,Athena和Quicksight实时分析Amazon Aurora数据库审计日志
Aurora高级审计功能介绍
关系数据库管理系统(RDBMS)通常支撑着最重要的联机交易类应用,存放着最重要的数据资产,所以在用户IT系统里占据着非常核心的位置。也正因为如此,不管是出于内在的数据保护的需求还是外部监管及合规的要求,数据库用户都需要对数据库的操作记录进行审计。传统的商业数据库管理系统(比如Oracle,SQL Server)也都提供了审计的功能,开源数据库MySQL也可以通过MariaDB审计插件提供此项功能。但现实情况往往是审计功能虽然使用并不复杂,但是鲜见有用户打开此功能。主要原因在于审计功能的对数据库性能的负面影响太大,特别是在业务负载较大的时候。这种情况下,数据库的审计功能成为鸡肋也就不奇怪了。
Amazon Aurora MySQL 1.10.1及其以后版本提供了高性能的高级审计功能,即使在开启审计功能的情况下依然能够保持数据库的高性能。那么Aurora是如何做到这一点的呢?我们可以对比一下MariaDB审计插件和Aurora高级审计功能的实现机制来找寻答案。
MariaDB审计插件使用单线程和互斥锁来记录每个审计事件,这种方式虽然能够严格保持事件的顺序,但是写日志产生的瓶颈对性能的影响也较大。为了维持Aurora数据库的高性能,在设计审计功能的时候使用了latch-free的队列方式存储审计事件,从而解耦了日志写和实际的业务操作。通过对队列使用多线程消费,写入到多个审计日志文件中。
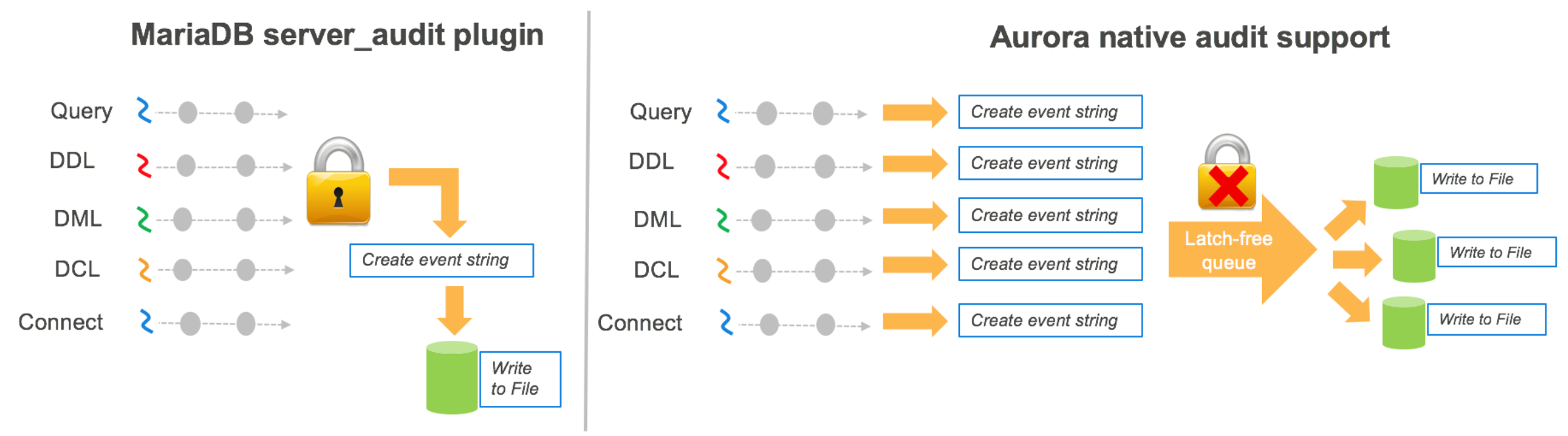
MariaDB audit plugin和Aurora审计机制对比
在8xlarge实例上对MySQL5.7和Aurora审计开关分别进行sysbench测试,MySQL5.7开启审计情况下对吞吐量有65%的影响,而Aurora仅有15%
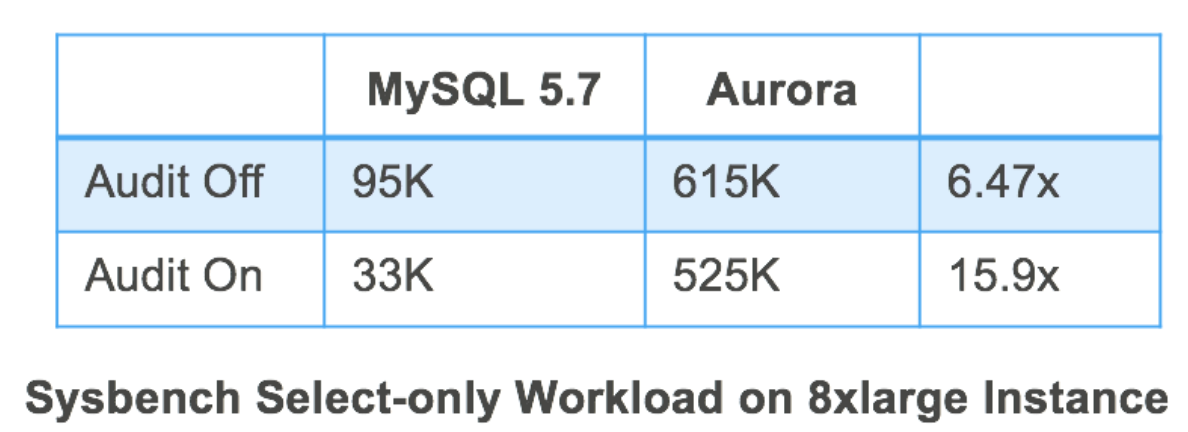 MySQL5.7、Aurora审计对性能影响对比
MySQL5.7、Aurora审计对性能影响对比
但是Aurora这种实现方式也存在一些不便之处,比如:
- 审计文件中日志中事件的顺序可能不是严格按照时间顺序排列,审计事件存放在多个审计文件中,需要后续进一步处理。
- 在console上虽然可以查看日志文件,但是不方便检索关键字。
- 审计文件存放在Aurora实例的本地盘上,遇到实例failure的情况,可能会丢失审计日志。
- 系统会根据空间使用情况以及日志文件的存放时间进行清理以释放空间,因此需要考虑备份和持久保存的问题。
幸运的是,在AWS上有很多服务不但可以解决以上问题,同时还可以很容易地构建一个自动化的无服务器架构的审计日志分析pipeline。本blog的以下部分将分别介绍:
- 使用CloudWatch Logs收集和管理审计日志
- 使用CloudWatch Logs subscription filter发送审计日志到Kinesis Firehose进行数据格式转换
- 使用Athena和QuickSight进行日志查询和可视化分析
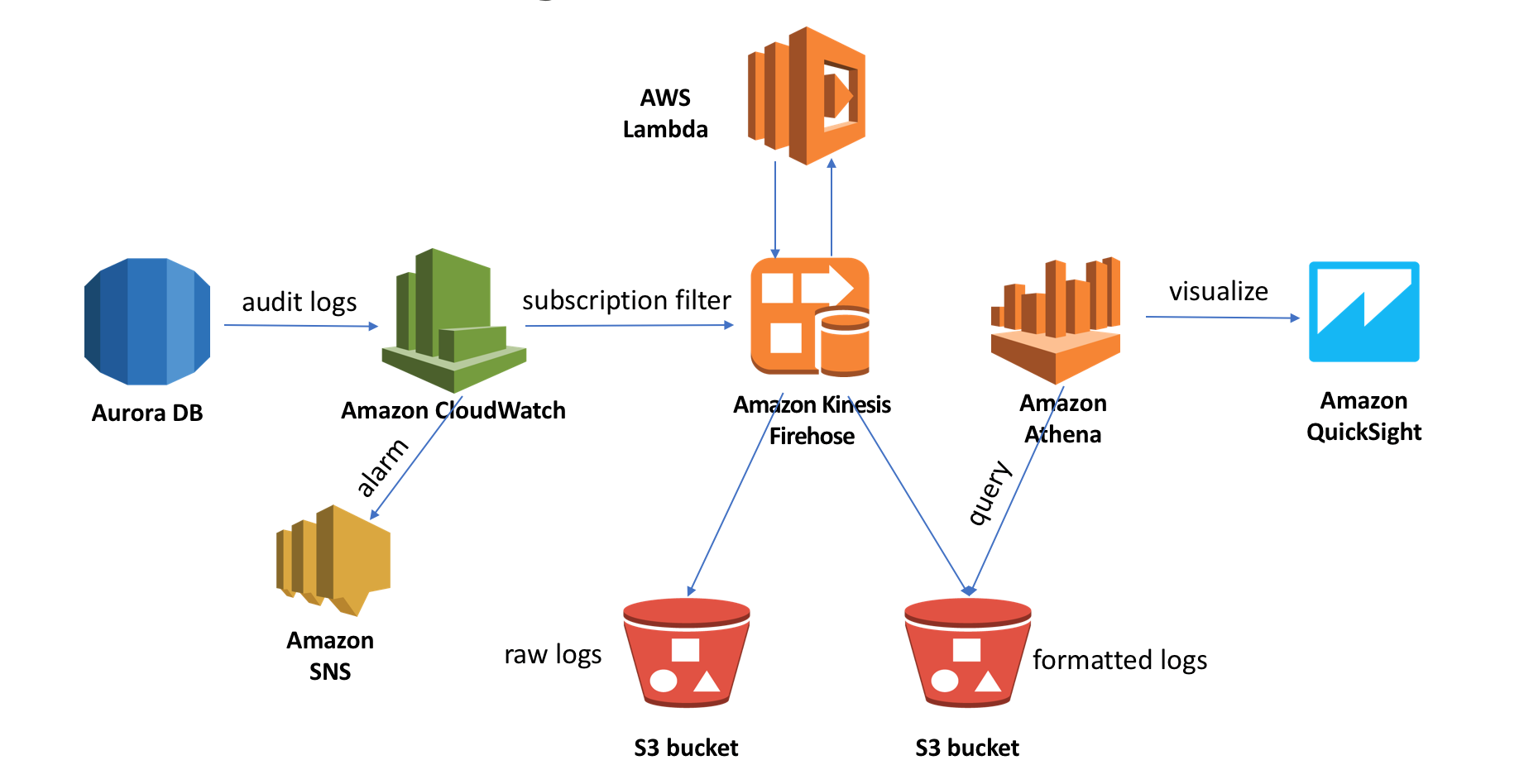
Aurora审计日志实时分析架构设计
使用CloudWatch Logs管理Aurora审计日志
要使用CloudWatch Logs管理Aurora审计日志,需要首先打开数据库的审计功能,然后赋予数据库集群发送审计日志到CloudWatch Logs的权限。
Step1: 打开集群的审计功能
登陆AWS管理控制台,打开RDS控制台,在左边的导航面板点击” Parameter Groups”,接着点击你的Aurora集群关联的参数组,然后选择“Edit Parameters”。
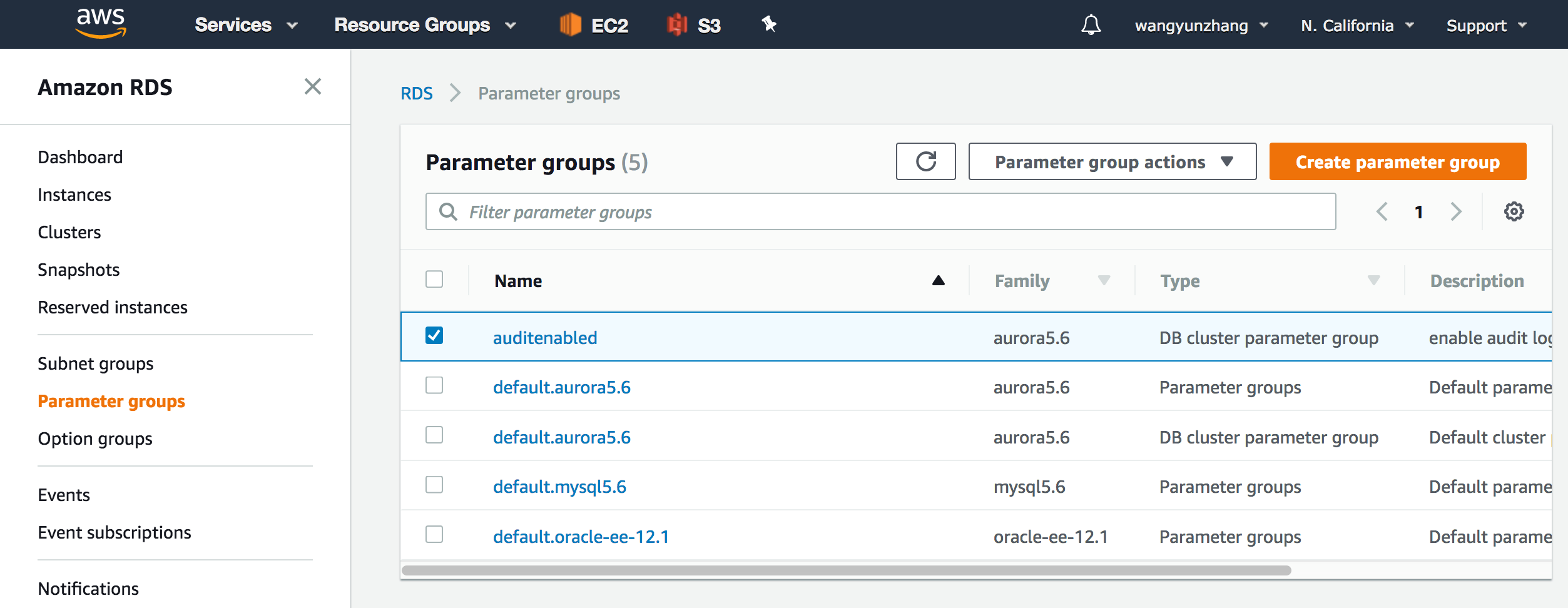
Aurora集群参数组管理
在过滤器里输入“server_audit”,设置server_audit_logging为1,设置server_audit_events, 输入你要审计的事件类型,类型之间用逗号分隔, 其余参数设置及详细说明参见Amazon Aurora MySQL 数据库群集使用高级审计。
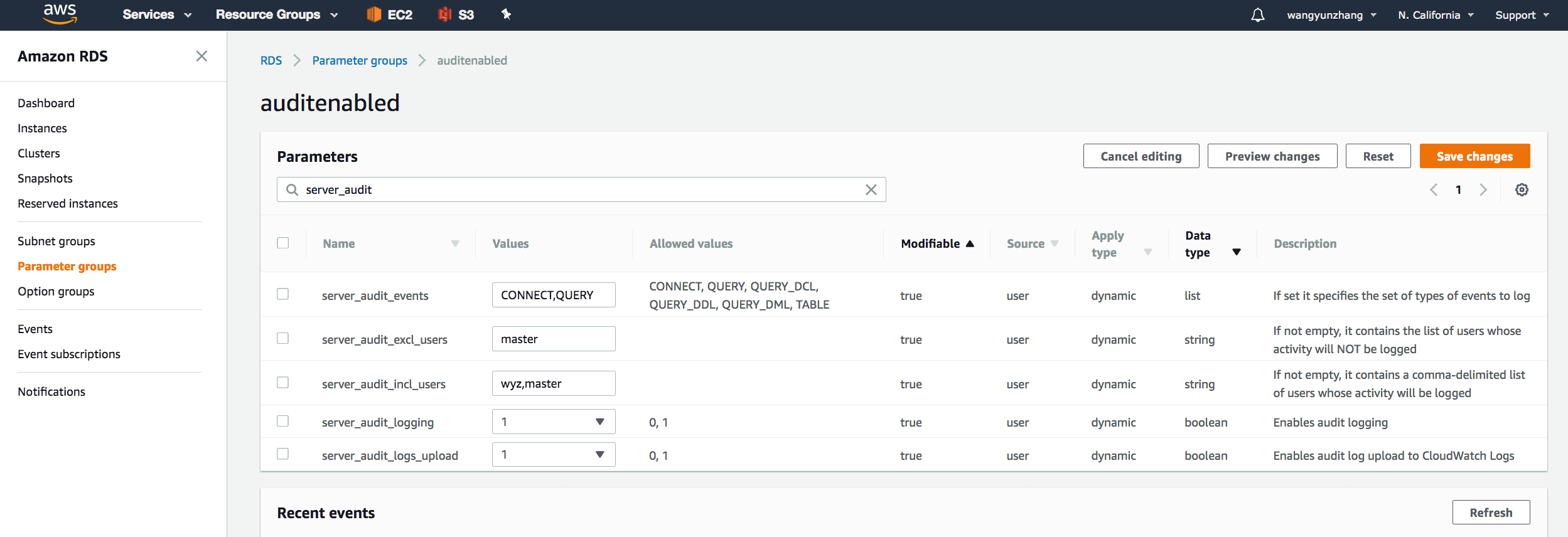
修改Aurora集群参数打开审计功能
以上设置打开了集群的审计功能,此时你可以导航到“Instances”查看Logs:
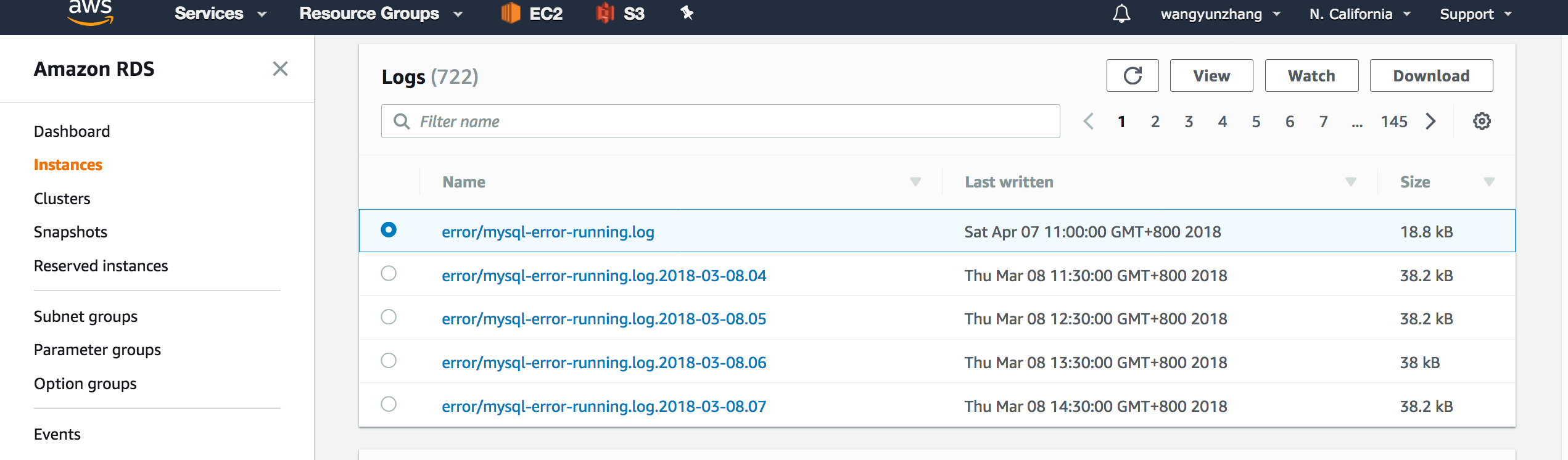
Aurora实例Log文件管理
Step2:赋予Aurora集群向CloudWatch Logs发送日志的权限,并打开发送开关
我们首先需要创建一个service role,你可以参照文档“将审核日志数据从 Amazon Aurora 发布到 Amazon CloudWatch Logs”,手工创建policy和role,也可以使用系统自带的AWSServiceRoleForRDS角色,它attach了AWS managed policy: AmazonRDSServiceRolePolicy,其中包含CloudWatch Logs发送日志需要的权限,在这里我们可以直接使用。
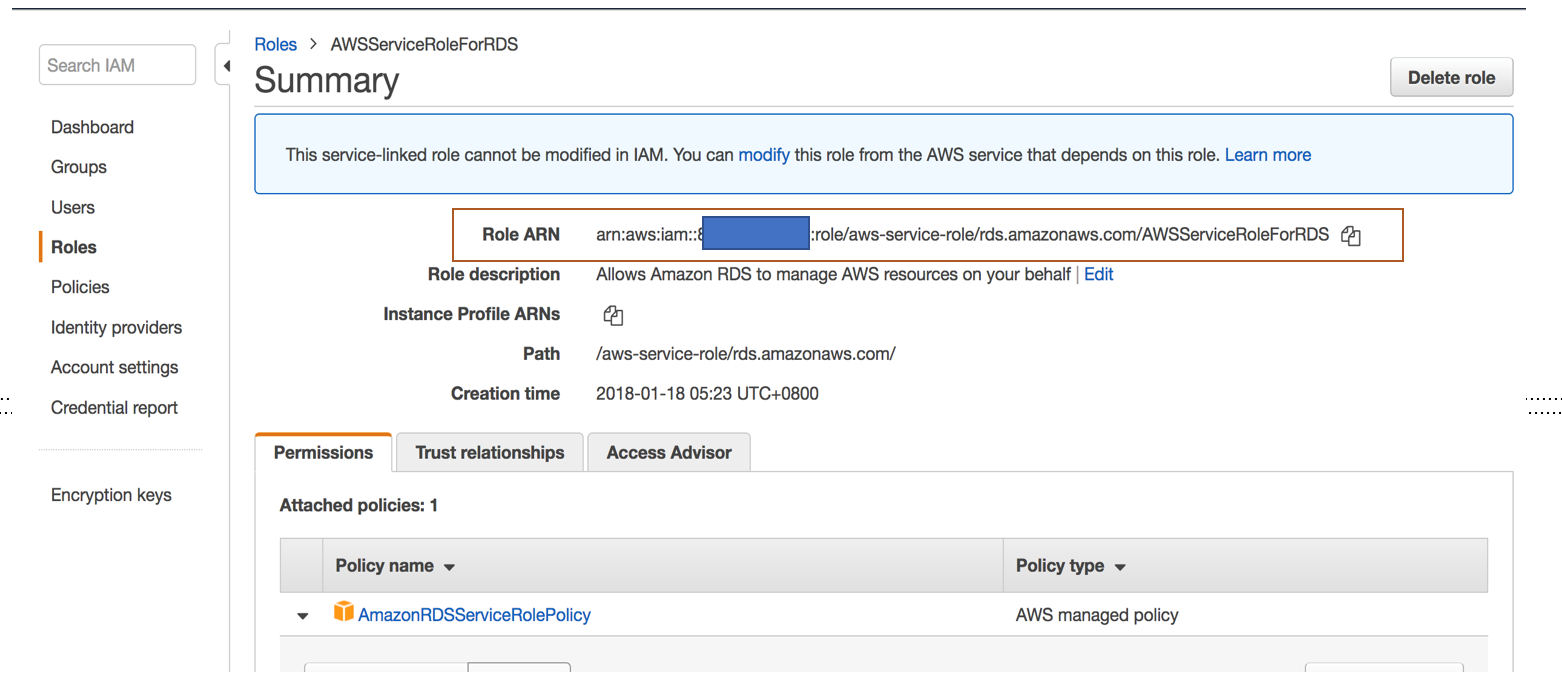
为Aurora集群创建CloudWatch Logs role
创建成果role 之后,记下Role ARN,打开cluster parameter,编辑aws_default_logs_role,设置参数值为记下的Role ARN,同时将server_audit_upload参数设置为1,该参数是upload的开关。
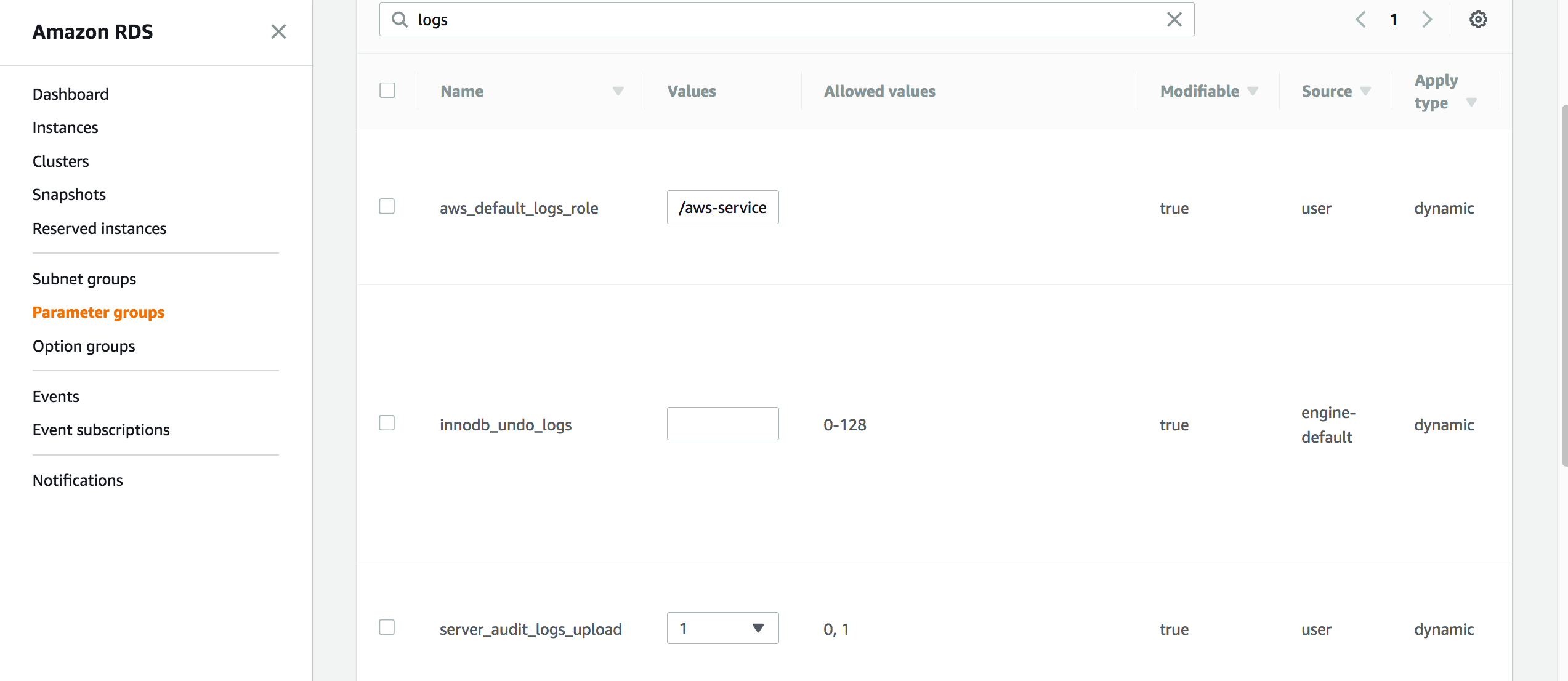
设置Aurora集群upload CloudWatch Logs
现在Aurora开始向CloudWatch Logs发送日志,查看日志请打开CloudWatch的console,点击Logs,找到/aws/rds/cluster/<your cluster’s name>/audit日志组
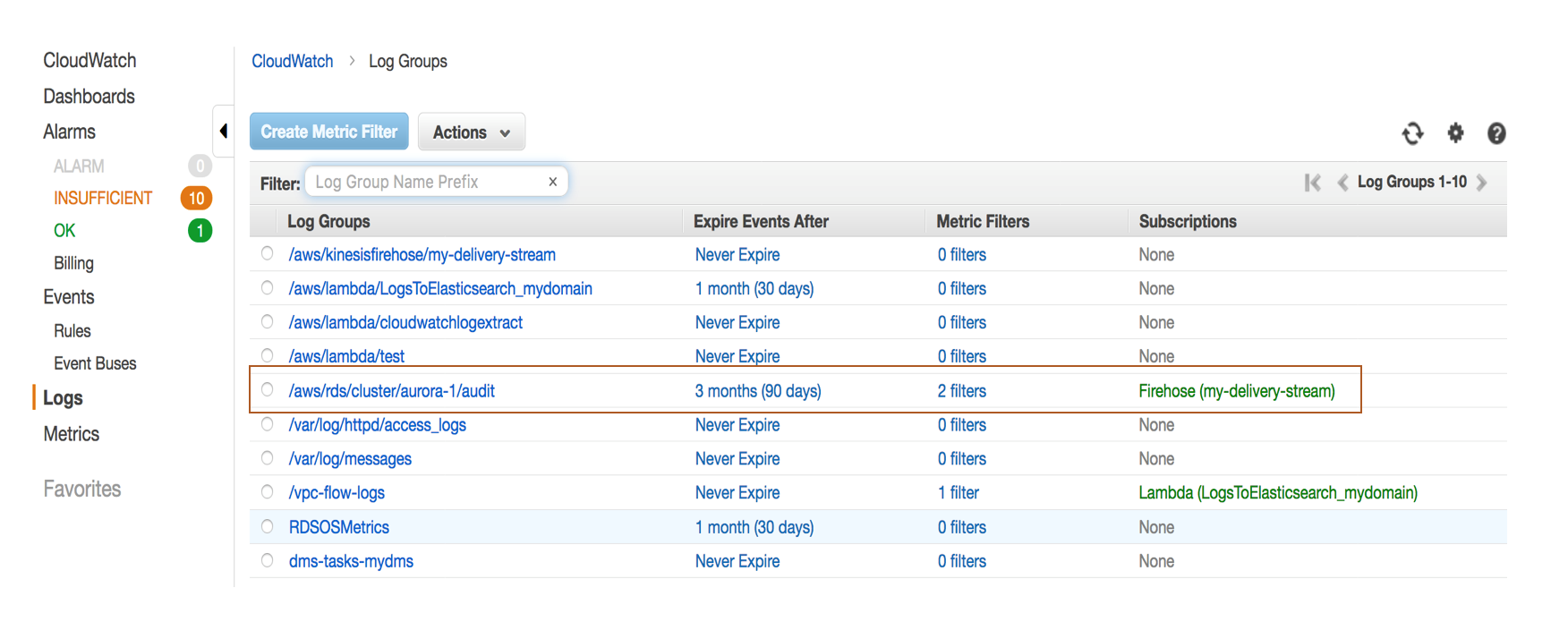 CloudWatch Logs中查看审计日志
CloudWatch Logs中查看审计日志
日志上传到CloudWatch Logs之后你可以:
- 查询和搜索日志
- 定义日志保存日期(默认永久保存)
- 自定义metric filter,比如对delete和drop table的SQL操作语句定义metric filter
- 根据自定义metric设置alarm,比如你可以定义drop table的时候自动发送告警短信或者email到管理员
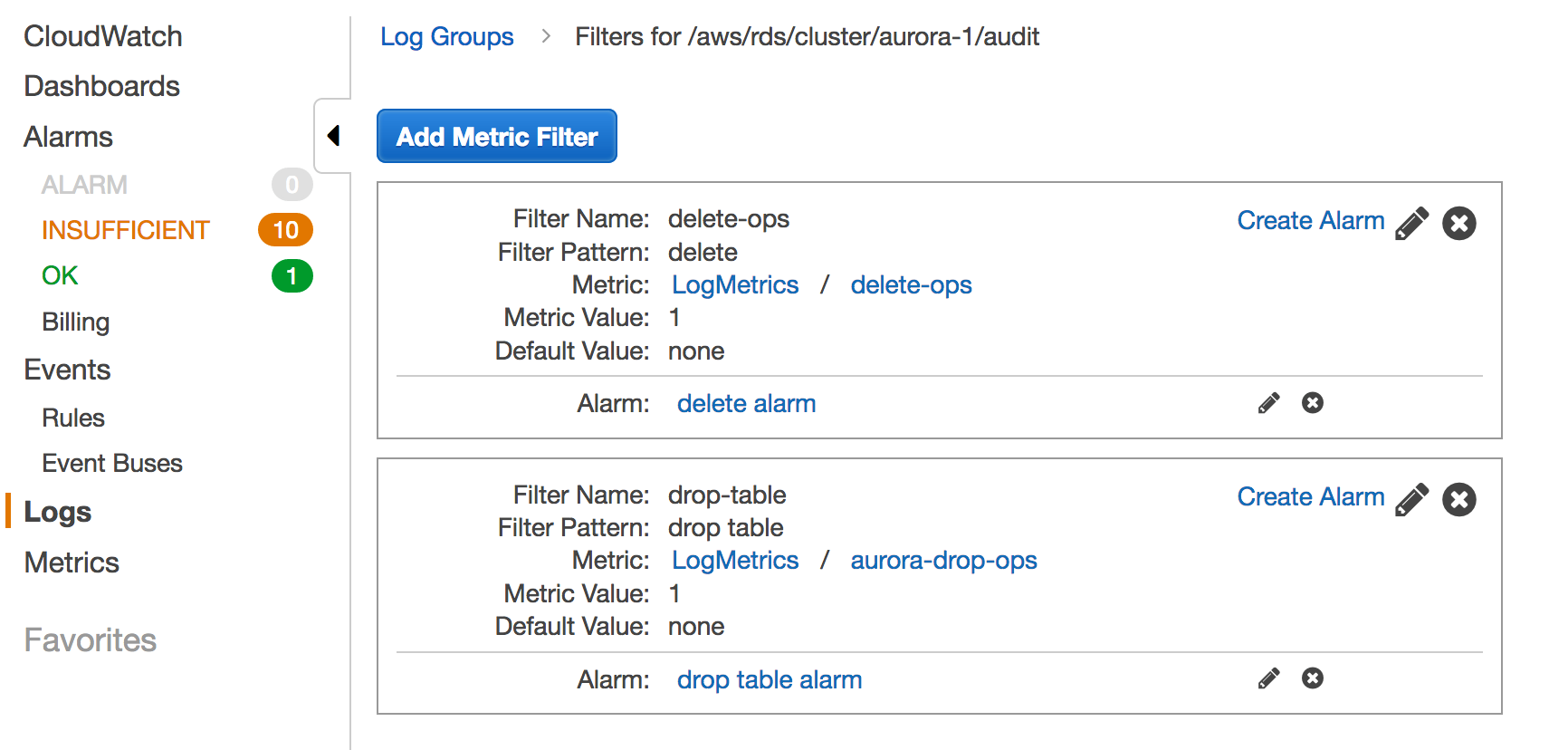
metric filter设置
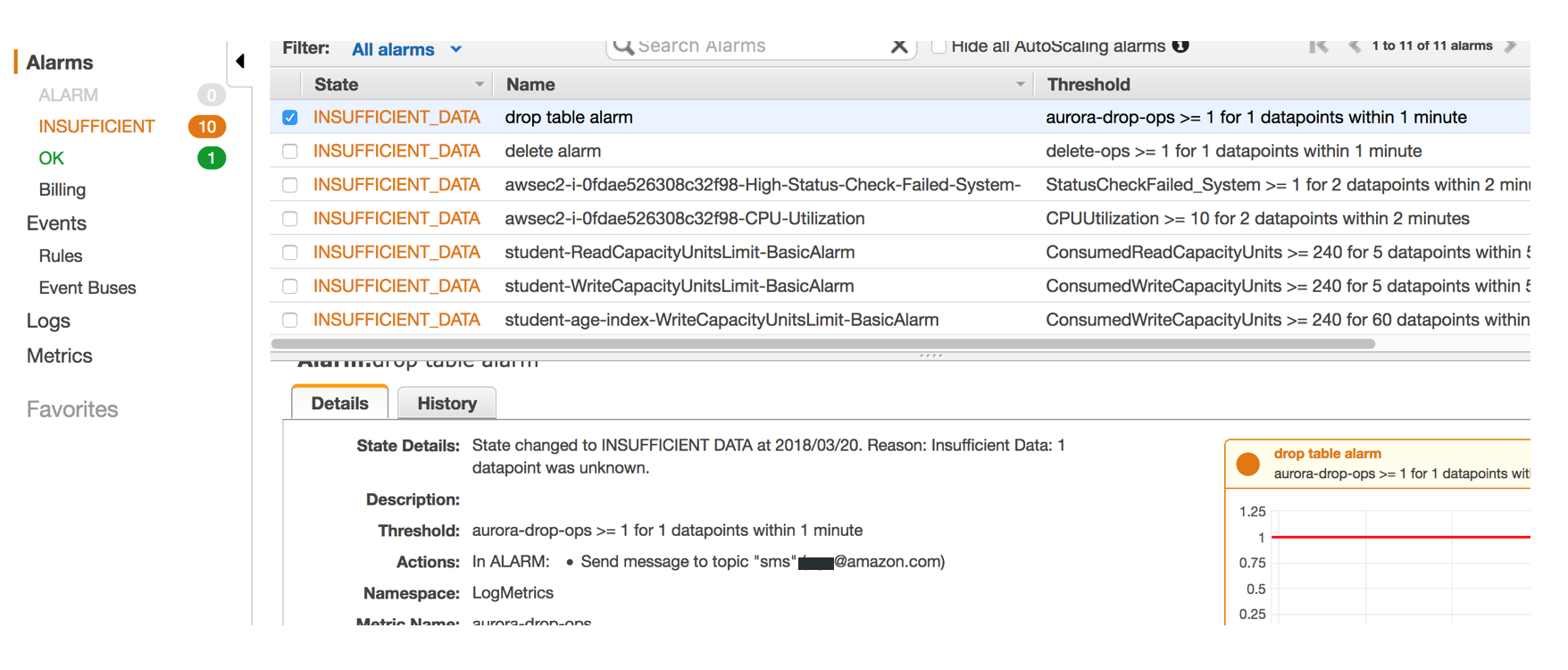
为审计日志设置Alarm
使用CloudWatch Logs订阅过滤器(subscription filter)将日志发送到Firehose进一步处理
CloudWatch Logs订阅可以从 CloudWatch Logs 中访问日志事件的实时源并将其传输到其他服务 (如 Amazon Kinesis 流、Amazon Kinesis Data Firehose 流或 AWS Lambda),以进行自定义处理、分析或加载到其他系统中。
Step1:为Kinesis Firehose建立subscription filter
该操作暂时不支持console,只能通过AWS CLI或者API进行,详细操作步骤请参考Amazon Kinesis Data Firehose 订阅筛选器,主要步骤如下:
为Firehose建立S3 bucket用于存放日志文件
- 创建 IAM 角色,该角色将向 Amazon Kinesis Data Firehose 授予将数据放入您的 Amazon S3 存储桶的权限
- 创建目标 Kinesis Data Firehose 传输流
- 创建 IAM 角色,该角色将向 CloudWatch Logs 授予将数据放入 Kinesis Data Firehose 传输流的权限
- 在 Amazon Kinesis Data Firehose 传输流进入活动状态并且您已创建 IAM 角色后,您便可以创建 CloudWatch Logs 订阅筛选器。订阅筛选器将立即启动从所选日志组到您的 Amazon Kinesis Data Firehose 传输流的实时日志数据流动:
aws logs put-subscription-filter \
–log-group-name “/aws/rds/cluster/aurora-1/audit” \
–filter-name “FirehoseDestination” \
–filter-pattern “” \
–destination-arn “arn:aws:firehose:us-west-1:1234567890:deliverystream/my-delivery-stream” \
–role-arn “arn:aws:iam::1234567890:role/CWLtoKinesisFirehoseRole” \
–region us-west-1
Step2:使用Lambda对日志进行格式化
step1完成了CloudWatch Logs实时发送到Kinesis Firehose,传送到S3的过程,但是这个日志是数据库实例产生的原始日志,日志字段之间使用逗号分隔没有问题,但是在“event”字段记录着数据库用户提交的SQL语句,由于语句内部可能存在逗号(比如select id, name from student),如果要使用Athena直接分析csv文件的话,会出现我们所不期望的将event字段分隔成多个field的情况,因此我们需要将event字段内部的逗号替换成空格字符。Kinesis Firehose可以调用Lambda函数完成该转换工作。
Kinesis Firehose 提供了“Kinesis Firehose CloudWatch Logs Processor”的Lambda blueprint,该blueprint可以完成对CloudWatch Logs subscription filter发送过来的log event的解析,我们只要修改其中的transformLogEvent函数,就可以完成类似”select id,name from student”转换为”select id name from student”的功能。修改后的代码如下:
def transformLogEvent(log_event):
“””Transform each log event.
The default implementation below just extracts the message and appends a newline to it.
Args:log_event (dict): The original log event. Structure is {“id”: str, “timestamp”: long, “message”: str}
Returns:
str: The transformed log event.
“””
#return log_event[‘message’] + ‘\n’ this statement is replaced by below to replace the “,” in sql with space
converted=””
temp=log_event[‘message’]
#print(temp)
templist=temp.split(‘\”)
for i in range(0,len(templist)):
if i%2==1:
a=templist[i]
templist[i]=a.replace(‘,’,’ ‘)
if i < len(templist)-1:
converted=converted + templist[i]+’\”
converted=converted + templist[len(templist)-1]
return converted + ‘\n’
step3:使用Athena对转换后的日志文件进行分析
在Athena控制台为日志文件创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS auroralog.audit_records (
`timestamp` bigint,`serverhost` string,`username` string,`host` string,
`connectionid` string,
`queryid` int,
`operation` string,
`mydatabase` string,
`object` string,
`retcode` int)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’
WITH SERDEPROPERTIES (
‘serialization.format’ = ‘,’,
‘field.delim’ = ‘,’
) LOCATION ‘s3://auroraauditlog/’
TBLPROPERTIES (‘has_encrypted_data’=’false’);
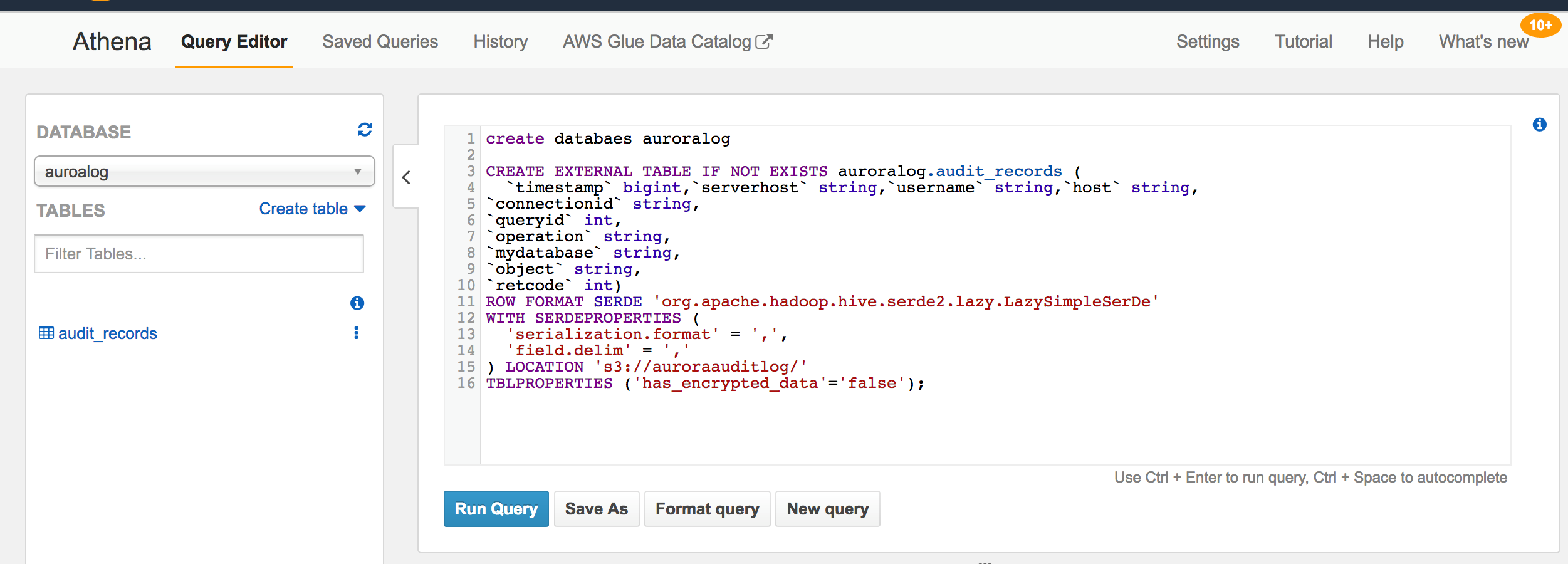
Athena console中创建database及external table
例如,我们可以查询某个时间段包含drop操作的审计事件:
select FROM_UNIXTIME(timestamp/1000000) as timestamp1,
username,
host,
operation,
object
from audit_records
where FROM_UNIXTIME(timestamp/1000000) >timestamp ‘2018-03-20 06:04:00’ and upper(object) like ‘%DROP%’
Step3:使用Quicksight可视化分析审计日志
现在我们有了审计日志在S3和Athena外部表,就可以很方便的通过几步点击使用QuickSight生成可视图表
打开Amazon QuickSight仪表板,选择”New analysis”,接着选择”New data set”,选择Athena作为数据源,并为数据源输入一个名字,接着选择“aurora”数据库和“audit_records”表,选择Select。选择SPICE 或者Direct query ,点击 “Edit/Preview data”,输入以下SQL查询而不是使用原表格,为Query输入一个名字,点击“Finish”,最后点击顶部栏的“Save & visualize”
select distinct queryid,
date_trunc(‘day’,FROM_UNIXTIME(timestamp/1000000)) as event_time,
username,
host,
connectionid,
operation,
mydatabase,
object,
retcode
from auroralog.audit_records
order by event_time desc
建立好analysis之后,就可以选择不同类型的visual type创建可视化分析,例如我们可以分析不同用户每天操作的次数:
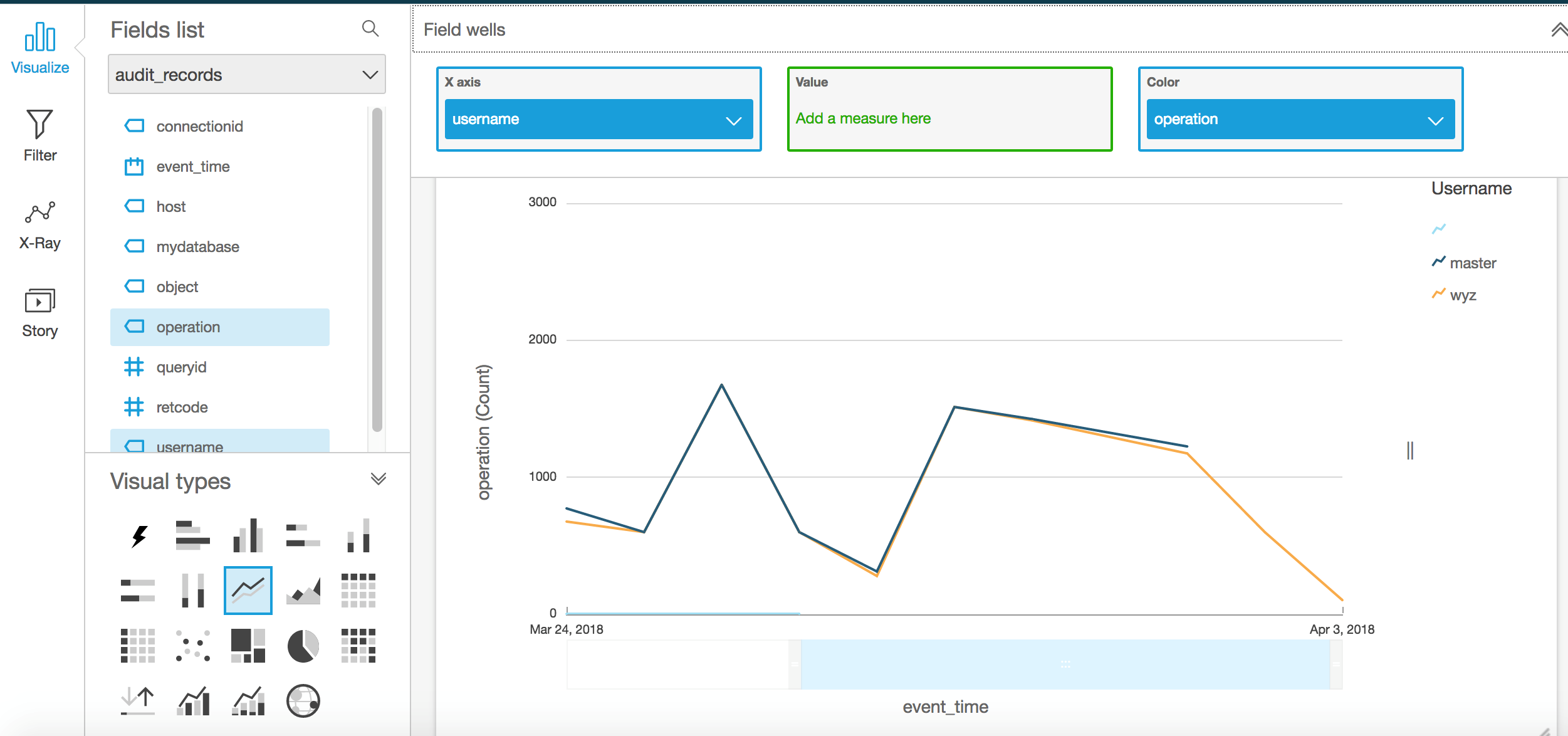
折线图
不同用户不同类型的操作次数:
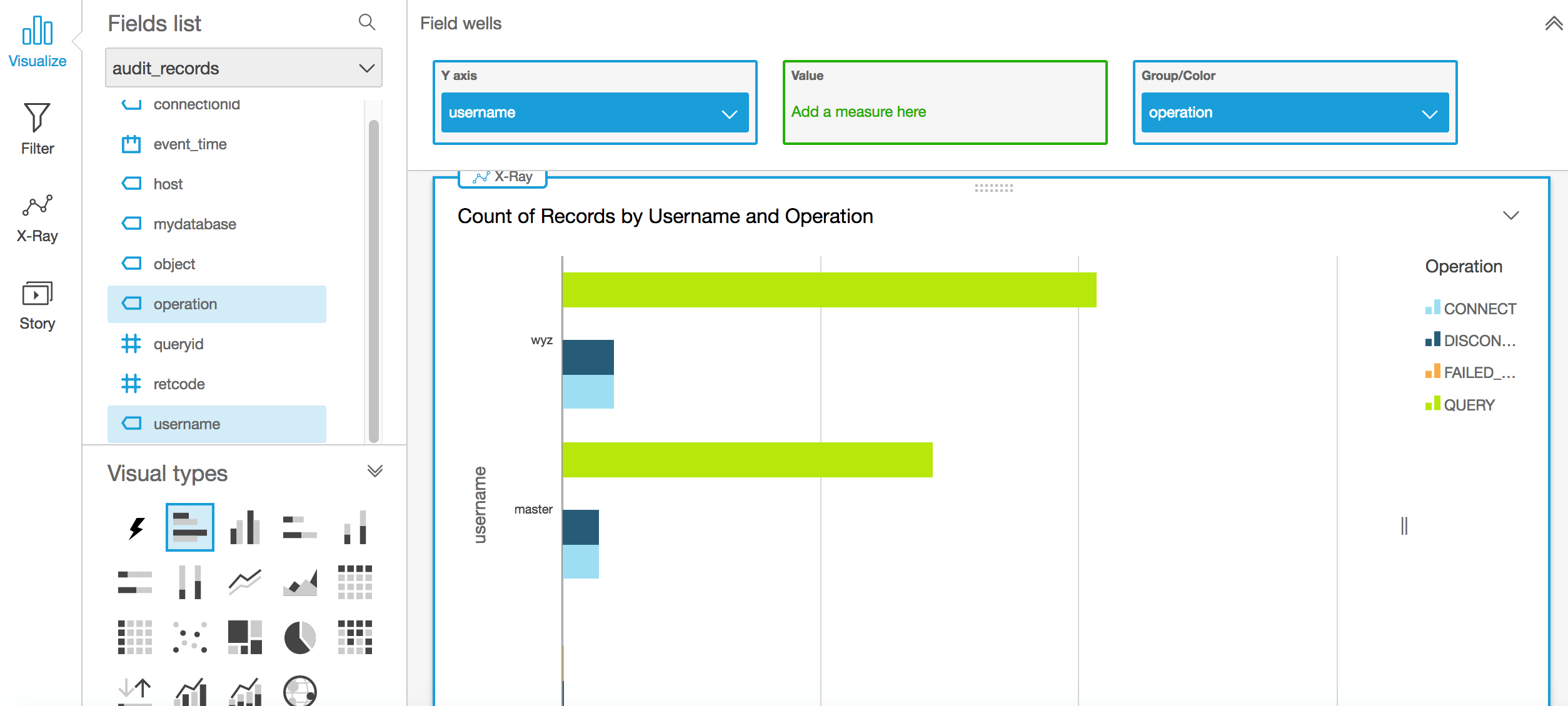
水平条形图