 QQ咨询
QQ咨询
使用Apache Kylin和Amazon EMR进行云上大数据OLAP分析
Kyligence为各行各业的客户提供基于AWS公有云平台的Hadoop数据仓库解决方案。Elastic MapReduce (Amazon EMR) 是AWS推出的云上Hadoop方案,这一方案使得Hadoop的部署、监控、扩容变的非常灵活方便。Amazon EMR将计算和存储分离,可以使用S3做数据存储,用户可随需启停Hadoop而不用担心数据丢失,用户只需为运行时使用的资源付费,从而大大减少运维成本。以最近发布的Apache Kylin v2.0和Amazon EMR 5.5(海外版)为例,在AWS云上使用Kylin是非常简单快速的。
1. 启动EMR集群
如果您已经有在运行的,包含了HBase 1.x服务的EMR集群,那么这一步可以跳过,您可以使用现有集群进行此实验。
EMR的启动非常简单,登录AWS控制台,选择Amazon EMR服务,点击“Create Cluster”,选择最新的5.5版本,类型为HBase:
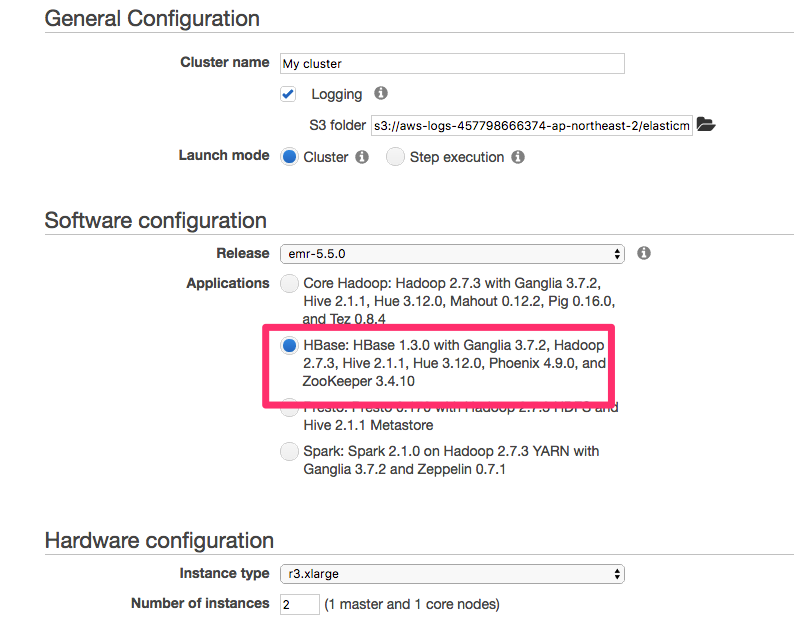
这里您可以选择合适的硬件配置;默认是m3.xlarge 3个节点,其中1个节点为master,另外两个为core节点。选择合适的EC2 key pair,随后点击“Create cluster”,AWS便会开始自动安装和配置Hadoop/HBase集群。
大约20分钟后,集群状态显示为“Waiting Cluster ready”,这意味着集群准备就绪可以使用了。
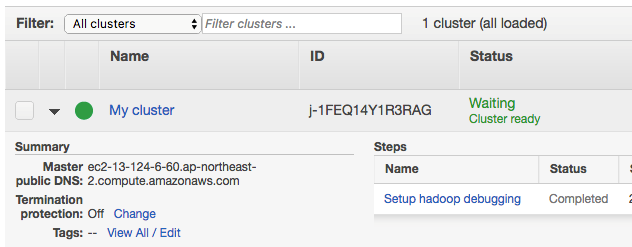
2. 安装Apache Kylin 2.0
Apache Kylin以Hadoop client的方式运行,使用标准协议/API与集群交互。您可以将它安装在集群的任意节点上,通常建议安装在一个单独的client节点上。在这里我们为了简单,就把Kylin安装在master节点上。
在AWS控制台上,您可以获取SSH到Amazon EMR的方法;点击“Master public DNS”旁边的SSH链接,即可获得,如下图所示:
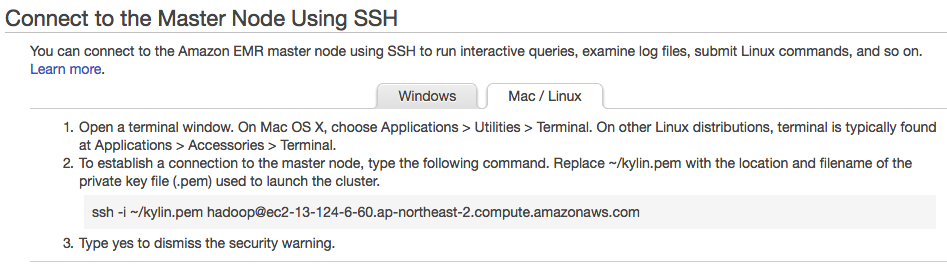
SSH登录到master节点后,创建一个Kylin安装目录,下载并解压Apache Kylin 2.0的二进制包:
sudo mkdir /usr/local/kylin
sudo chown hadoop /usr/local/kylin
cd /usr/local/kylin
wget http://www-us.apache.org/dist/kylin/apache-kylin-2.0.0/apache-kylin-2.0.0-bin-hbase1x.tar.gz
tar –zxvf apache-kylin-2.0.0-bin-hbase1x.tar.gz
如果下载速度较慢,可以至Kylin官网寻找并使用更接近的下载镜像。
由于一个已知的问题KYLIN-2587,您需要手动在Kylin里设置一个参数:用编辑器打开/etc/hbase/conf/hbase-site.xml,在其中寻找到“hbase.zookeeper.quorum”这个参数,然后将它以及它的值,拷贝到Kylin目录下的conf/kylin_job_conf.xml文件中。如下所示:
<property>
<name>hbase.zookeeper.quorum</name>
<value>ip-nn-nn-nn-nn.ap-northeast-2.compute.internal</value>
</property>
(注意请使用在您环境中真实获得的zookeeper地址)
3. 创建sample cube并启动Kylin
Kylin自带了一个小的数据集以及定义好的cube,只需要运行bin/sample.sh就可以将数据导入到Hive和HBase中:
export KYLIN_HOME=/usr/local/kylin/apache-kylin-2.0.0-bin
$KYLIN_HOME/bin/sample.sh
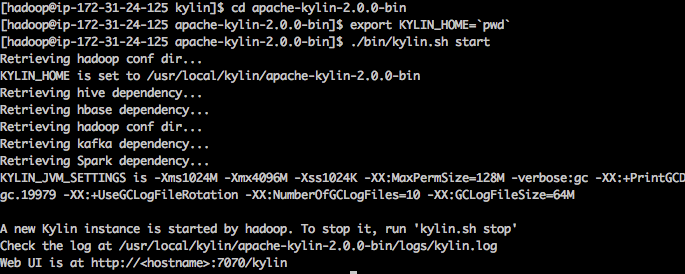
随后,就可以启动Kylin了:
$KYLIN_HOME/bin/kylin.sh start
大约若干秒以后,Kylin服务就会完成启动,在7070端口等待用户请求。
4. 修改安全组以允许访问Kylin
Amazon EMR默认创建了两个安全组,分别给Amazon EMR master和Amazon EMR core,要想从外网访问Kylin,需要设置相应规则;这里我们是将Kylin部署到了master节点,所以需要编辑master的安全组:
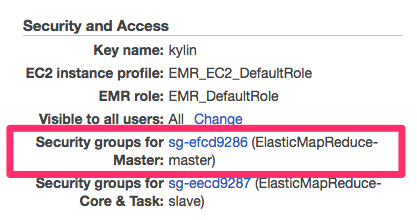
添加规则,允许7070端口从外面地址访问,为安全起见,建议只开放给最小的IP群,例如仅自己的地址:

接下来,在浏览器中输入http://<master-public-address>:7070/kylin,就会显示Kylin的登录页,使用默认账号ADMIN加密码KYLIN完成登录:
5. 构建Sample Cube
登录Kylin后,选择“learn_kylin”的项目,就会看到“kylin_sales”的样例Cube。此Cube模拟一个电商对其销售记录从多维度进行分析的场景,维度包括了时间(天,周,年)、区域、卖家、买家、商品分类等。
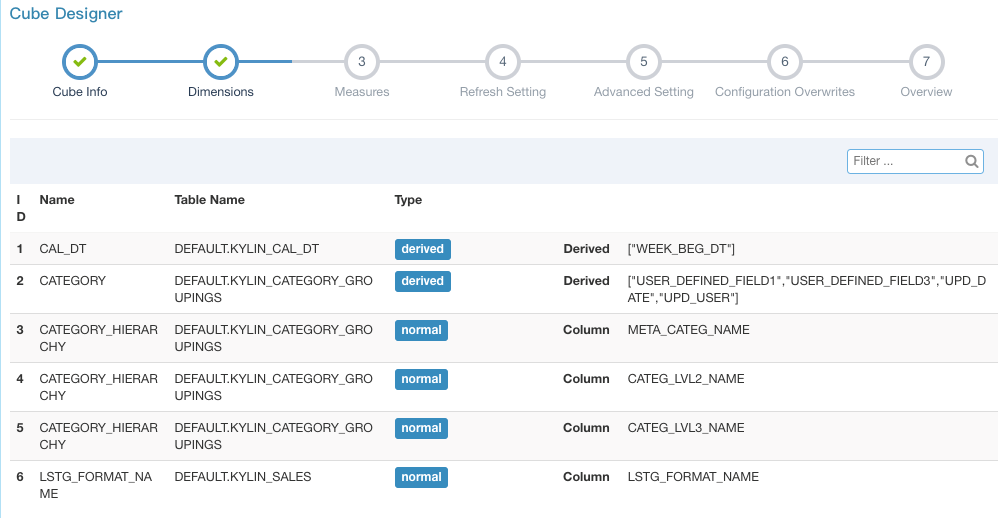
此时Cube只有定义,还没有加载数据,状态是“disabled”,需要触发一次Build。点击“Actions”,“Build”,然后选择一个时间范围,Kylin会以此条件从Hive加载数据进行一系列计算(样例数据已经导入到Hive):
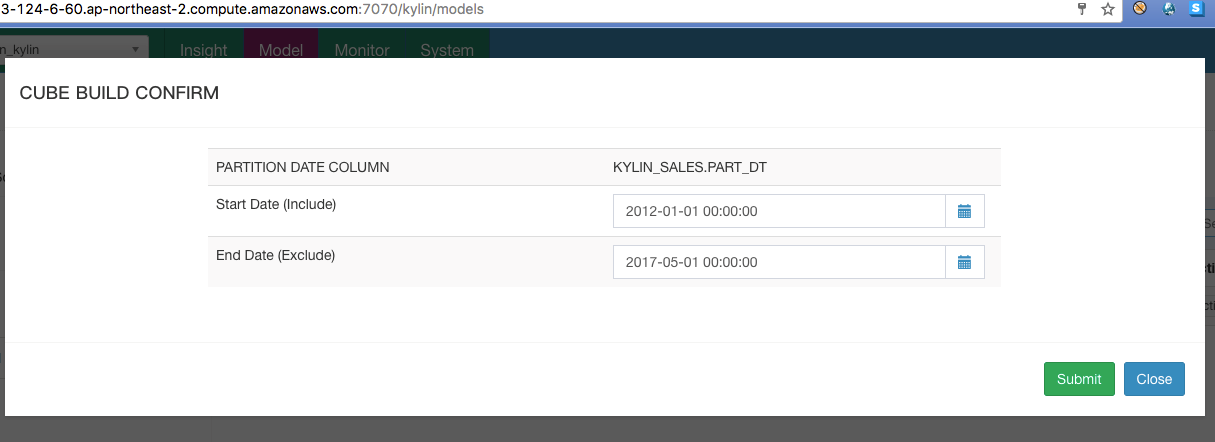
所有的MapReduce, Spark, HBase操作,Kylin会自动生成并依次执行。大约七八分钟后,任务进度到100%构建完成,接下来此Cube就可以使用了:
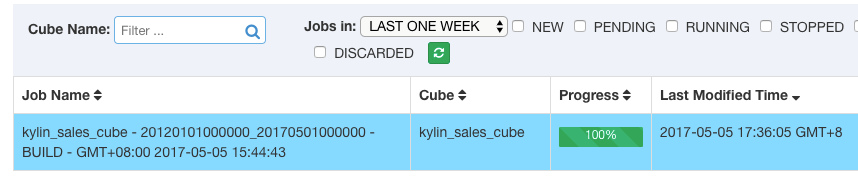
6. 查询Cube
Cube构建完成后状态变更为“Ready”,可以使用SQL对其进行查询。虽然Kylin将原始数据构建成了多维Cube,但是对外的查询接口依旧是标准SQL,且表名、字段名依然是用原始的名称。这意味着用户一方面可以不用学习新的工具和语法,另一方面以前在Hive中执行的查询语句,基本上可以直接在Kylin中执行。
在Kylin主页点击“Insight”,切换到查询视图。此时页面的左导航处显示可以通过Cube进行查询的表和列。这里您可以尝试手写一条SQL,如下面的这条语句,按年计算交易总金额和记录数:
select YEAR_BEG_DT, sum(price), count(*) from kylin_sales inner join kylin_cal_dt on part_dt = cal_dt group by YEAR_BEG_DT;
点击“Submit”,Kylin随即执行并显示结果,如下图所示:
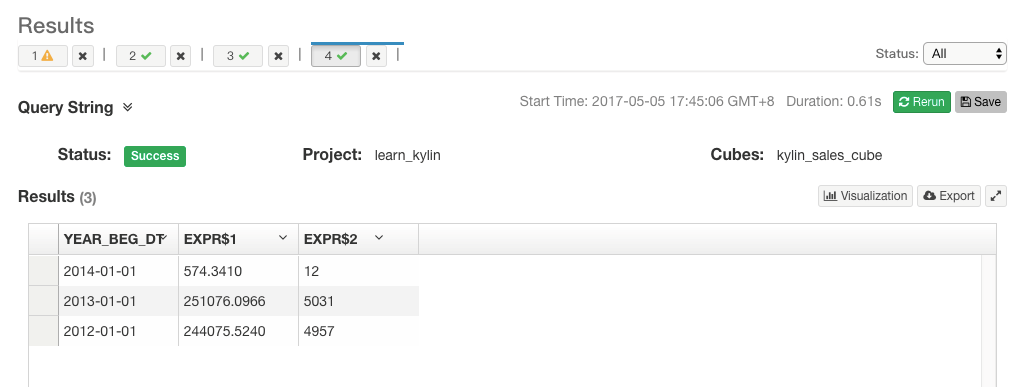
至此您已经完成了在AWS上运行Hadoop + Kylin的任务!从上图可以看出,Kylin的执行只耗费了0.61秒,接下来您使用可视化工具如Tableau, Excel, Saiku, Zeppelin, SmartBI等通过Kylin的ODBC/JDBC驱动连接Kylin server,体验交互式OLAP分析。
使用完以后,记得关闭Amazon EMR集群以节省费用。
成功案例
Strikingly基于AWS公有云和Kylin搭建了大数据解决方案。Strikingly (https://strikingly.com/)是一个简单、易用、美观的Web建站平台,产品中有一个面向用户的 Web Analytics Dashboard,它从各个维度以及不同时间尺度上展现了用户网站包括 Unique View, Geo Distribution 等数据,如下图所示。
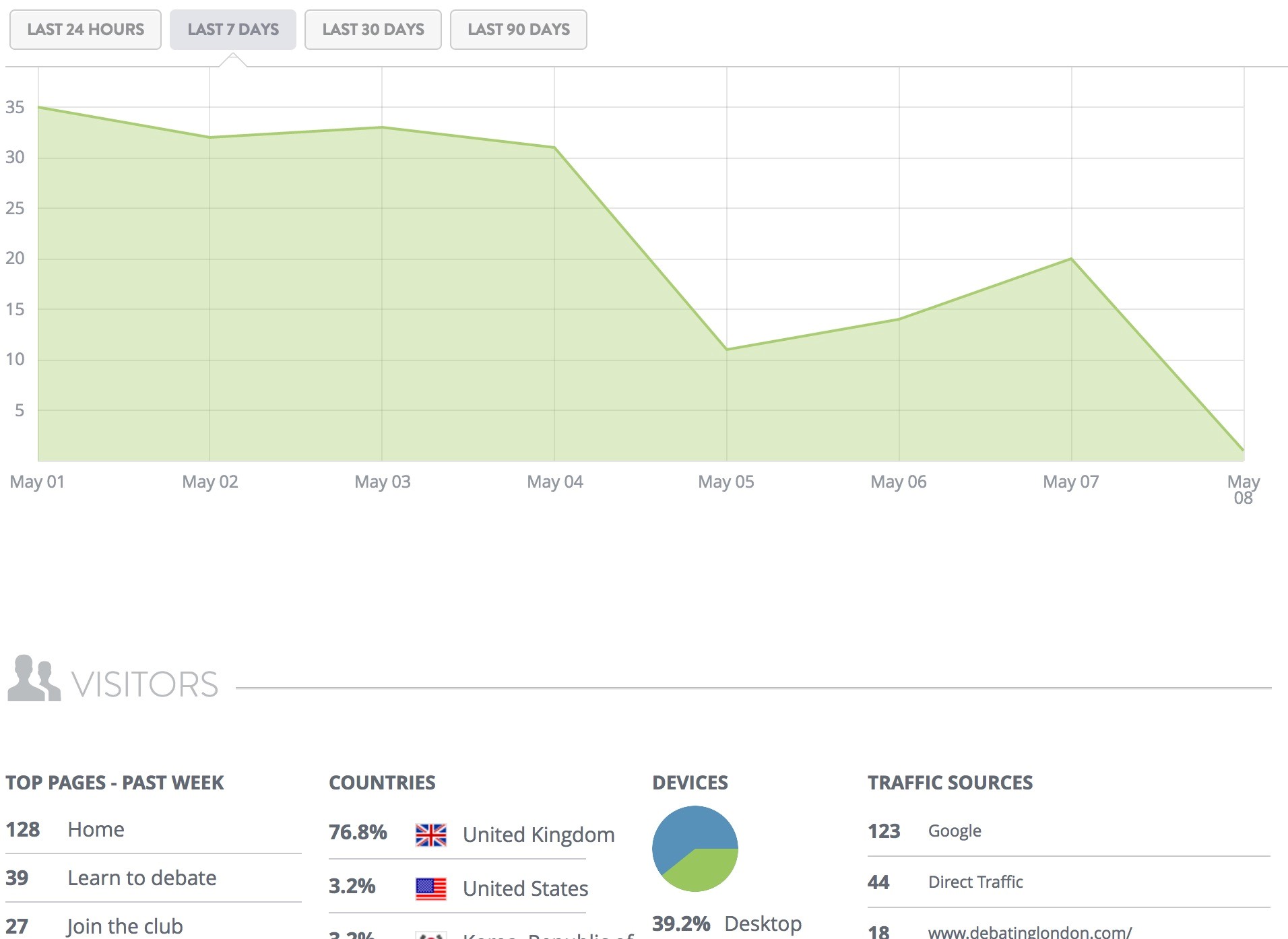
用户数据查询的类型主要集中于对于各个维度数据的 group by 和 count distinct,都是比较耗时的查询操作。随着数据规模不断增长,以往的解决办法面临性能瓶颈。研究之后,Strikingly采用了Kylin + Amazon EMR的方案:每隔5分钟将原始数据备份到指定的S3 bucket上。通过预先定义好的Lambda函数对原始数据进行处理,转换成Kylin + Amazon EMR可以处理的数据格式,然后交由Kylin + Amazon EMR计算。通过引入Kylin,成功将数据查询的延迟从5~10秒降低到了1秒以内。当数据量增加的时候,可以通过Amazon EMR控制台动态添加core machine横向扩展服务,提高吞吐能力,这保证了可以对未来一段时间内可以预见的数据规模增加提供足够的技术支撑。
总结
借助于独有的分布式预计算技术,Apache Kylin比其它各类OLAP引擎能提供更高的查询性能和并发能力,并且随着数据量增加,查询延迟依旧可以保持在亚秒级(参考Kylin的SSB测试:https://github.com/Kyligence/ssb-kylin)。近些年云计算技术日趋成熟,越来越多的企业正在将大数据分析迁移到云上,AWS无疑是很热门的选择,而在选择大数据OLAP方案时,低延迟、高并发、可扩展是重要的考虑因素,Kylin结合Amazon EMR可以使云上的大数据分析变得简单而强大。